
Mistral — A Journey towards Reproducible Language Model Training
Team: Jason Bolton, Tianyi Zhang, Karan Goel, Avanika Narayan, Rishi Bommasani, Deepak Narayanan
Tatsunori Hashimoto, Dan Jurafsky, Christopher D. Manning, Christopher Potts, Christopher Ré, Percy Liang
Authors: Siddharth Karamcheti and Laurel Orr
We introduce and describe our journey towards building Mistral, our code and infrastructure for training moderate scale GPT models in a plug-and-play fashion. We also release artifacts — 5 GPT-2 Small/5 GPT-2 Medium models, with different random seeds and 600+ granular checkpoints per run!
tl;dr :: We are the development team (colloquially referred to as the “Propulsion” team) for the Center for Research on Foundation Models (CRFM). We are incredibly excited to introduce Mistral — a simple, accessible codebase for large-scale language model training, based on the Hugging Face Ecosystem. This post describes our journey (the ups and the downs) in training modest-sized GPT-2 Small and Medium models (up to 355M parameters).
Training these models wasn’t as straightforward as we hoped. We faced several hurdles and subtle “gotchas” in the process of getting stable, repeatable training. We realized through this process that there is still a lot of research to be done in large-scale language model training. To support research into training dynamics, especially across randomness, we’re releasing a full set of 5 GPT-2 Small and 5 GPT-2 Medium models trained on open-source data with different random seeds, including 600+ granular model checkpoints per run! We’re also releasing our training dashboards (via Weights and Biases) and logs for these runs as well as our failed runs! Even though our initial codebase focuses on language models, we’re looking forward to studying other types of foundation models as well.
Nothing in life is to be feared. It is only to be understood.
-- Marie Curie
The Status Quo
Several industry entities have successfully trained massive models that demonstrate impressive capabilities — OpenAI (GPT-3 [Brown et. al., 2020]), AI21 Labs (Jurassic-1), NAVER (HyperCLOVA [Kim et. al. 2021]), Microsoft (Turing-NLG), and Google (T5-11B [Raffel et. al., 2019], mT5-XXL [Xue et. al. 2020]) to name a few. Industry has done an amazing job showing us what these models can do through publications and public APIs. However, to the best of our knowledge, many of the above models (especially the large ones) have not released training code, data sources, and complete implementation details — certainly none that meet the common standards reproducible ML research [Pineau, 2020]. Understandably, this has made it difficult for the broader community to study these large models and answer pressing questions around their capabilities and safe use.
Outside of industry, these concerns motivated efforts like those by students from Brown University and the grass-roots community EleutherAI (creators of GPT-J [Wang and Komatsuzaki, 2021], GPT-Neo [Black et. al., 2021], and GPT-NeoX [Andonian et. al., 2021]) to try to replicate, extend, and publicly release massive language models. Currently, the most powerful freely and publicly available autoregressive language models are GPT-J and GPT-Neo (2.7B), with ongoing efforts by the BigScience Project and EleutherAI to train 13B and 22B models respectively.1 In addition, work like Grover [Zellers et. al., 2019] and Train Large, then Compress [Li et. al., 2020] used Google TPU hardware and pre-existing trainers to reproduce and train large-scale models with the public cloud. Driving further research are recent open-source implementations from industry labs, like NVIDIA’s Megatron-LM, a highly-optimized codebase for training large-scale transformer models for NLP and Vision in PyTorch.2
Enter “Propulsion”
As academics who want to study large LMs and other foundation models, our objective was not to build the biggest models or have the fastest training code to start with. Instead, our main goal was to make it easier for researchers like ourselves to study and answer scientific questions about these models — from understanding how the training data impacts the learned model to establishing paradigms of stable training in mixed hardware compute environments. As we started talking about these goals within Stanford, we found pockets of other researchers in disciplines ranging from law to political science who shared our vision. This led to the creation of CRFM (see this post for more information and CRFM’s report on foundation models).
As we started our journey, our natural instinct was to use what was already out there —- why reinvent the wheel? We quickly noticed that existing efforts were focused on generating useful artifacts (e.g., the ability to train a large LM), rather than on the process by which these artifacts are created, i.e., the systematic study of how these models are developed and trained. This isn’t to say that these existing efforts aren’t valuable: these artifacts are extremely important. They’ve established communities to lean on and resources to learn from and compare against. But we believed there was room for a more process-oriented perspective.We laid out a few desiderata</a> for training infrastructure that were important to us and would make form a series of considerations for us (and hopefully others in this space) to think about as they research training and developing new models:3
-
Simplicity: Code that is easy to read, understand, and run — especially to an audience that doesn’t have deep expertise in ML systems, infrastructure, and scaling. For us, this included many of our peers within major AI disciplines (NLP, vision, robotics, amongst others), as well as our friends in social science, law, healthcare, and other non-ML disciplines.
-
Community: Infrastructure that is conducive to collaboration and open-source development. This includes leveraging support and feedback from other communities and adopting pre-existing tools, community-curated datasets and benchmarks, if possible.
-
Flexibility: Implementations that can be inspected and modified to suit a variety of use-cases and needs. We need code that can be modified in a day to study a research hypothesis or implement a new idea.
-
Transparency: Clearly documented code that demystifies any and all “heuristics” used for data preprocessing, training stability, and model evaluation. Documentation that describes how to spin up training, and support for multiple hardware platforms, especially commodity hardware.
-
Reproducibility: An implementation that clearly separates and makes available all hyperparameters important to training, as well as makes it easy to replicate existing training runs reliably with minimal effort.
-
Pedagogy: Infrastructure organized in a way that can be used to empower, educate and train future researchers and engineers. All that we (and others in the community) have learned about language model training — best practices, tips, solutions to common problems — should be reflected in our code, documentation, and APIs.
-
Scalability: Lastly, we want infrastructure that can eventually scale to larger heights (and that doesn’t preclude or place any hard limits on this axis), only because it allows us to study larger model regimes and emergent properties like “in-context learning” that, thus far, are out-of-reach with smaller models.
With these desiderata in hand, we spend the rest of this post describing our journey building training infrastructure to train GPT-2 language models up to 355M parameters (GPT-2 Medium). This post encapsulates the stumbling blocks and interesting questions we hit along the way, and our plans for the future. Our real goal here is to point out the non-obvious walls we hit while scaling.
We’ll discuss how we decided what starter code to use, which tools to lean on, and the other challenges we encountered spinning up our codebase. We’ll end with discussion about what’s next, and where we think you — the community — can help!
One does not simply train a GPT-2.
-- A Futurist Parallel-Universe Version of Boromir (probably)

The Journey Begins in an Infrastructure Forest
The first step was to pick the right infrastructure. Asking a team of software engineers (especially researchers) to decide on infrastructure is akin to asking someone for their favorite ice cream flavor; there are trade-offs that impact the decision but no “right answer.” Figure 2 shows the various approaches we considered, pros/cons for each, and an associated ice cream flavor.4 Specifically, we thought about:
-
Rolling our Own: Building a codebase from scratch. Full control over APIs, but no out-of-the-box compatibility with other open-source projects. Lots of troubleshooting, but transparent (to a point). It would be expensive and hard to maintain — this was a no-go.
-
Megatron-LM: Fast for GPUs and battle-tested. Used to train some seriously large models (11B+ GPT-style models with preliminary tests of trillion parameter models). Yet… a bit opaque and not quite geared for hacking and adaptation. It requires more technical expertise than we wanted — another no-go.
-
GPT-Neo: Fast for TPUs with lots of development support, but changing quickly when we started our work.5 Built with Mesh-Tensorflow, and mostly geared for TPU training on the TF Research Cloud. The key issues were opacity, unfamiliarity with Mesh-TF, and a desire to move beyond TPUs (we weren’t sure of our funding sources, and if we couldn’t use Google Cloud Platform — GCP — TPUs were out of the question).
-
Hugging Face 🤗 Transformers: An API familiar to the majority of the NLP research community and also gaining industry traction. Crisp model definitions, trainers that were integrated with recent tools for efficient training like FairScale and DeepSpeed and a demonstrated history of support. Most imporantly a massive and dedicated community.
Weighing the different infrastructure choices against our desiderata (Figure 2) we decided to use Hugging Face (HF) Transformers. This wasn’t an easy decision; Transformers wasn’t designed, nor (to our knowledge) had it been used with the explicit intent of training large-scale models (most of our labmates and colleagues used it for fine-tuning or evaluation). Even Hugging Face’s BigScience effort uses a fork of the Megatron-LM codebase in their effort to train a GPT-3 sized language model. Yet while the Transformers codebase was not battle-tested for training large models, the open source community behind it was. By moving forward with Transformers, we placed our trust in this community, and throughout the last few months, they’ve really come through.
Spinning Up — Challenges
While building off of the ecosystem Hugging Face gave us a really nice template to follow (HF Datasets → HF Tokenizers → HF Models/Configs → HF Trainer), there were still plenty of techniques and tools to familiarize ourselves with:
-
Understanding mixed precision training and the intricacies thereof (like dynamic loss scaling. For completeness, we also looked at other codebases (especially those geared for TPUs) that looked at different 16-bit precision modes like Brain Float 16. Though theoretically better for stable training, brain floats were unsupported by our stack at the time.6
-
Understanding new tools being integrated into Hugging Face like DeepSpeed & ZeRO that showed remarkable promise for faster distributed data parallel training (by cutting down on memory footprint per GPU, allowing for bigger batches without increasing communication latency).
-
Reading about other forms of parallelism for using multiple GPUs (tensor model parallelism, pipeline model parallelism) that are necessary for scaling beyond a couple billion parameters. When we started, these were a bit opaque and hard to integrate with existing HF code. We hope to implement some of these advances for future versions of our codebase and have already started discussing this with folks from Hugging Face.
Spinning Up — Tools
We first wanted to understand the trade-off space of the different design decisions behind large-scale training including hyperparameters, parallelism, and other scaling tools (e.g., DeepSpeed). After extensive benchmarking, we settled on mixing the HF Trainer with mixed precision training, and plugins like DeepSpeed’s ZeRO Stage 2 Optimizer. A lot of these choices were specific to the size of the models we were training. We hope to write further posts that dig deeper into how to weigh these trade-offs, and revisit some of these choices in light of the new tooling that’s become available since we started. Now that we have v1 done and are beginning work on v2 of Mistral, addressing our performance gaps and inefficiencies is our current big challenge!
Another key part of this initial “ramp-up” with our codebase was investing time into building an expansive suite of logging tools.7 Built with Weights & Biases (W & B), our logging comprised trackers for activation norms per-layer, losses, gradient norms before and after clipping, and various timing statistics. Due to the beautiful GUI and streaming updates W & B provides, not only did this end up letting us identify bugs quickly, but they let us shut-down long-running, failed jobs – saving time and lots of money!
Spinning Up → Spinning Out
The biggest challenge came with model training, where we encountered major stability issues. That large-scale Transformers are subject to unstable training by itself isn’t surprising. There are enough details in existing work that allude to this [Liu et. al., 2020]. Things like the need for a learning rate warmup prior to gradual decay (present in the original Transformer paper [Vaswani et. al., 2017]), to more bespoke strategies that only seemed to be necessary at immense scale (for example, at »1B parameters, there’s a need to linearly increase the batch size from a small value up to its full value over a moderate number of steps [Brown et. al., 2020; Appendix B]). What was surprising to us is that even with the “best practice” tricks in place (the learning rate schedule that has become commonplace in Transformer code and sane hyperparameters lifted from papers and public implementations), we were still having problems with crashing runs — crashes that stemmed directly from numerical stability.
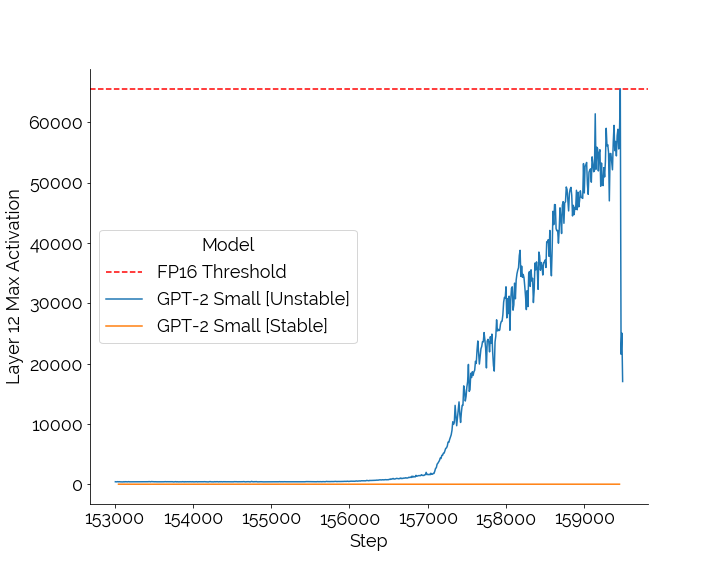
Diagnosing Numerical Instability
tep one was diagnosis, and this is where our extensive logging showed its worth. We looked at per-layer activation norms and found that on some runs, the value of the attention weights in the scaled-dot product attention (basically a massive dot-product operation) were “blowing up” (not in a good way), overflowing in 16-bit precision.8 This happened at different points in different training runs and was more pronounced as we scaled to larger models. We kept checking our codebase for glaring omissions and errors, but amongst our group and other groups at Stanford, there wasn’t anything obvious we could find. All we knew boiled down to the following: our model worked when training with full precision, but (frequently) failed without it.
Stuck as we were, we reached out to other folks whose main suggestion was to adjust hyperparameters. All implementations are different based on slight design choices (e.g., do I scale prior to or after the dot-product?) and one implementation’s learning rate doesn’t necessarily mesh well with another — meaning even numbers reported in papers weren’t completely helpful. We ran the gamut; learning rates, the Adam Optimizer’s Beta1 and Beta2 values, and the amount of weight decay we used, but all attempts came up blank. At this point, we were desperate, so we did the honorable thing… and looked to other codebases (thanks to NVIDIA and EleutherAI for open-sourcing Megatron-LM and GPT-Neo). We peered into the depths of their code with an eye on FP16 training.
Eureka!
Interestingly, we couldn’t find anything at a surface level. But diving deeper, scanning the GPT-Neo codebase, we saw imports of key Transformer code from the underlying, well-supported Mesh-Tensorflow library. Tracing this further, we saw this interesting argument (set by default to True!) in the attention function implementation. Concretely, with Mesh-TF, to get around the scaled dot-product attention stability issues we were seeing, the specific dot-product operations are “upcasted” to be in the more stable FP32 paradigm. In other words, the best way to prevent overflow in this specific part of the model was to just expand the numerical range and “skip” the problem entirely. Looking at the Megatron-LM codebase, we saw signs of the same problem handled a bit differently In addition to upcasting to FP32, the Megatron-LM code further divides the key-vector by the layer index, scaling the magnitude of this vector down by the depth of the network. This heuristic ensures that the norm of the key vector never gets high enough to cause overflow when the dot-product operation is implemented.
A Rallying Cry
The fact that these fixes exist isn’t the problem. They make sense and solve specific problems. Where we take pause, though, is in their transparency; there isn’t community knowledge about what sorts of problems exist and how to fix them — in other words, nothing prevents other groups from stumbling upon similar problems when they try to scale their own training code. Following this is a concern that seems to be crucial now, more than ever; many papers don’t have all the details necessary for replication [Lipton and Steinhardt, 2018], [Dodge et. al., 2019]. Yet as these systems are deployed, studied, and generally become widely adopted, we are at the point where it feels harmful to hide any design choices. The GPT-3 paper [Brown et. al., 2020] doesn’t mention the precision they trained with (presumably it’s mixed precision, but what type? Were some operations upcasted? Other heuristics?), nor do they even talk about the structure of their model parallelism in detail. Even code and models trained using TPUs sometimes don’t disclose that, and even if they do, often don’t disclose the precision (e.g., 32-bit or BF16) being used.
Upshot?
Ultimately, in order to mitigate any stability issues, we implemented both the layer-wise scaling and FP32 upcasting in our scaled dot-product attention layers. The code we release is transparent about this, and this functionality can also be turned off via a top-level flag. But as a result of these fixes, we’re able to say that we can robustly train GPT-2 Small and GPT-2 Medium models on varying numbers of commodity GPUs (and nodes) with relative ease. Are we happy and satisfied that we had to incorporate these heuristics to stabilize our model training — No! While our runs converged, there are still many of them that potentially show “structural flaws,” as indicated by the loss scale values being noticeably lower for some runs compared to others (see our W&B dashboard if curious). And we don’t know if our models are the only ones that show this, or if this plagues other models as well (and if so, what that means in terms of downstream applicability). We will keep digging and continue our mission — to understand and be transparent around what goes into training these models.
Looking forward, we want to deepen our understanding of these stability issues (and more!). That they show up on the smaller scale has us wary about what we (and others) have encountered scaling to much larger models: from the 1-2 billion, to the 10-15 billion, to the 100+ billion parameter range. We’re excited to tackle these challenges, and we’re more excited to talk with others in industry, in academia, and in other independent communities about these problems as well. Ultimately, this is why “propulsion” exists — to help inspect, evaluate, and ultimately build a sturdy foundation we can use to train myriad diverse, broadly capable models.
And miles to go before I sleep, And miles to go before I sleep.
-- Robert Frost
As part of our journey, we are releasing our training infrastructure Mistral Mistral provides an easy-to-use and transparent large-scale GPT language model training infrastructure (more models coming soon). It is built using HuggingFace Trainers and Datasets with some customizations: a modified GPT-2 model definition that handles the upcasting and layer scaling described above and native DeepSpeed support. To facilitate ease of use, we provide plug-in-play GPT configurations (through our very own Quinine Configuration Library) and quickstart guides for getting set up on Google Cloud Platform via the Google Kubernetes Engine to train models cost-effectively! Check Figure 4 for an example of how to get started training your own GPT-X model on an arbitrary number of GPUs with a single command!
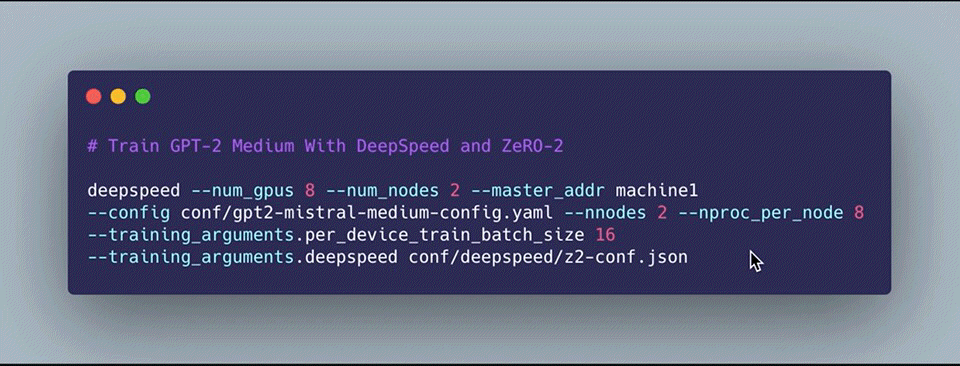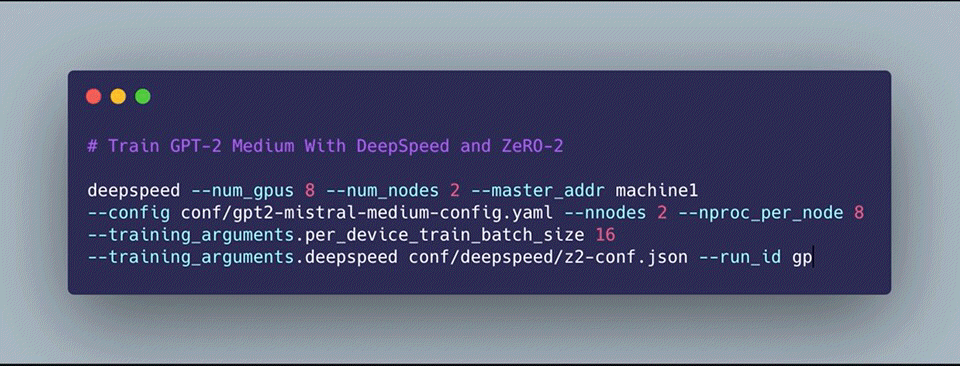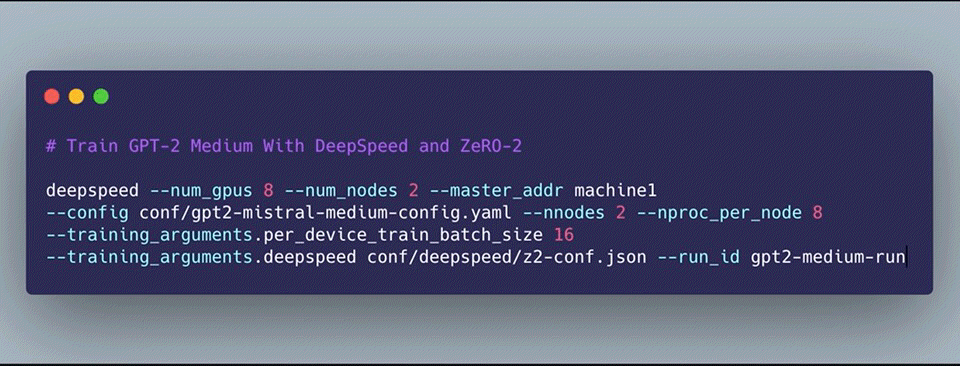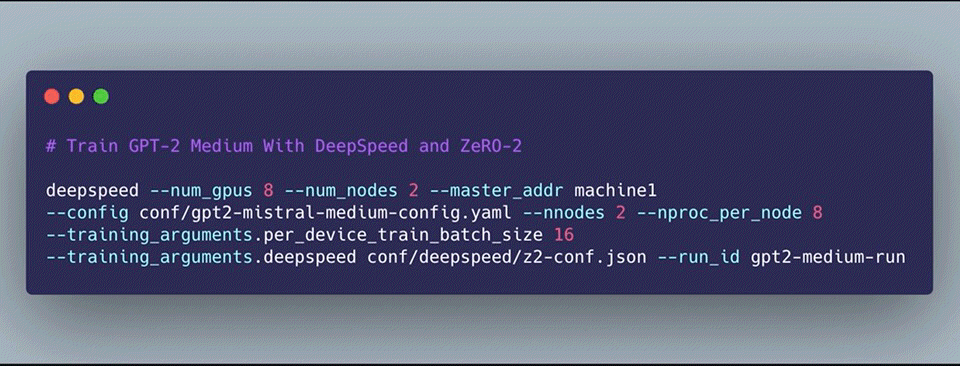
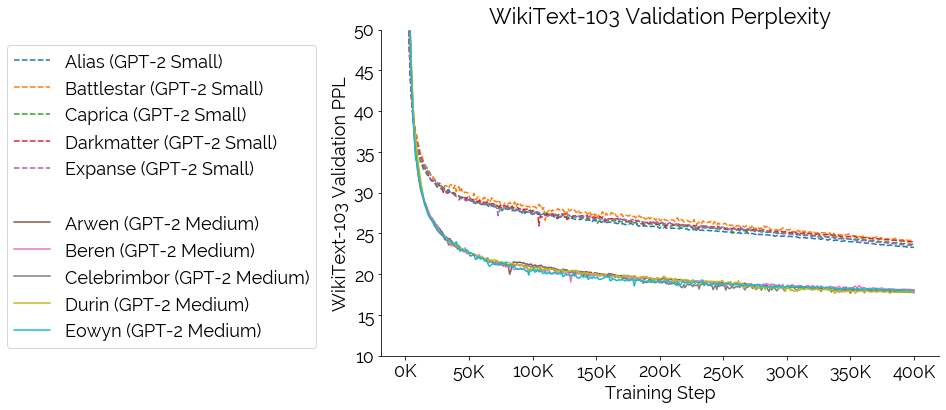
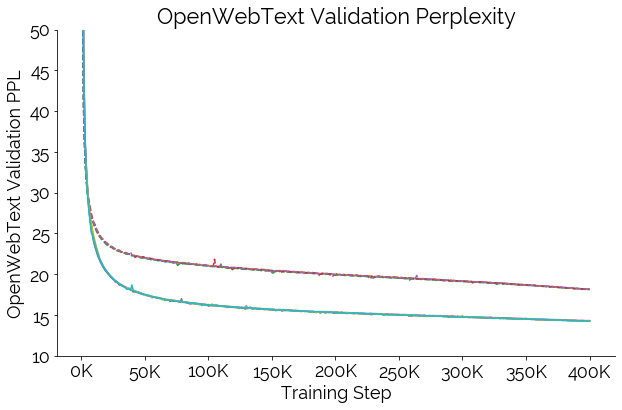
In addition, we want to encourage research into interpretability and evaluation, especially around looking at the effects of randomness and learning dynamics. To this end, we’re releasing all our training artifacts and W & B dashboards (including the failures!) for a set of 5 GPT-2 Small (124M) and 5 GPT-2 Medium (355M) models (evaluation results shown in Figure 5).
Each model has a different random seed and, for reproducibility, is trained on OpenWebText for 400K steps. To capture dynamics, we generate 610 checkpoints for each model. Hosting 22 TB without download restrictions is a bit expensive 😅, so our initial fully public release only has a small subset; however, do not hesitate to reach out for the full set of 600+ per run — we can figure out the best way to get them to you (external drives + the postal service perhaps 😂).
As for us… well we’ve got quite a bit in store. We remain committed to work on Mistral, and to make it even easier to use, faster, and more cost-effective. We’re adding new models (BERT, T5), expanding to support new applications and modalities, and incorporating a series of optimizations from other codebases (with help from Hugging Face, Megatron-LM, EleutherAI, and DeepSpeed). Our ultimate goal is to get Mistral integrated back into HuggingFace so researchers across domains can easily train their own (possibly smaller scale) language models. But we hope to be intentional about how we contribute code back — sticking to the desiderata above, while also ensuring we’re not sacrificing too much in terms of performance. In other words, a large push (with folks at HF and the wider community) will be around how to get Megatron-LM or “streamlined” training performance, while maintaining Hugging Face’s standards for accessibility. It’s going to be a big effort, but we’re committed and eager to continue our work!
Contributing
Thank you all so much. If you’re interested in helping to build or extend our codebase (it’s not perfect — efficiency bugs, low-hanging fruit like adding code for other models!) drop an issue on Github!. And if there’s a larger project on your mind and you want to collaborate, feel free to shoot us an email!
Miles to go, indeed
Acknowledgements
Weights & Biases (especially
Carey Phelps) came
through for us in a big way — logging, debugging, and run tracking would have been impossible
otherwise. We’d also like to thank those at HuggingFace
(Thomas Wolf,
Stas Bekman)
for their support, and for answering our questions throughout this process.
A massive shout-out to EleutherAI for
letting us learn from you, trade and discuss ideas, and generally
letting us lurk in your Discord.
You’ve set an incredible bar for what a community looks like and how it should operate. Special
thanks to Stella Biderman for
editing and providing feedback on this blogpost!
Finally, we would never have achieved lift-off without the amazing Propulsion team —
Jason Bolton,
Tianyi Zhang,
Karan Goel,
Avanika Narayan,
Rishi Bommasani, and
Deepak Narayanan. We’re also
incredibly excited that we’re growing – shoutout to
Keshav Santhanam and
Tony Lee. Finally, we’re incredibly
grateful for the encouragement and ardent support of our advisors
Tatsunori Hashimoto,
Dan Jurafsky,
Christopher D. Manning,
Christopher Potts,
Christopher Ré, and
Percy Liang.
Citing Mistral
@misc{Mistral,
author = {Karamcheti, Siddharth* and Orr, Laurel* and Bolton, Jason and Zhang, Tianyi and Goel, Karan and Narayan, Avanika and Bommasani, Rishi and Narayanan, Deepak and Hashimoto, Tatsunori and Jurafsky, Dan and Manning, Christopher D. and Potts, Christopher and Ré, Christopher and Liang, Percy},
title = {Mistral - A Journey towards Reproducible Language Model Training},
url = {https://github.com/stanford-crfm/mistral},
year = {2021}
}
Footnotes
These newer models are completely open-source and are trained on large, diverse datasets like the Pile [Gao et. al., 2020]. ↩
These are representative examples, and are by no means exhaustive. Many large-scale models are being developed in industry and academia, with the field moving quickly; check out our report on Foundation Models for more discussion, as well as efforts to track global model scale like the Akronomicon. ↩
These desiderata reflect the values that we prioritized in making decisions; by making them explicit, we follow the advice of Birhane et al. (2021) of making our values clear, and we hope to hold ourselves accountable on delivering on these values as we continue to grow. ↩
This list is by no means exhaustive — it wasn’t exhaustive back when we started this endeavor, and it’s far less complete now, as more companies and initiatives like Hugging Face and BigScience are open-sourcing new datasets, tools around data curation and evaluation, and more! ↩
We note that since we started, EleutherAI has come out with a new codebase, GPT-NeoX that is PyTorch native and well-equipped for GPU training, based on Megatron-LM. ↩
New NVIDIA GPUs (Ampere) like the 3XXX series and A100s in combination with PyTorch 1.9 support BF16s natively — we’re excited to try this out soon! ↩
In the words of some wise man — build thy logging strong and exhaustive, lest you spend $$$ on cloud compute for a 3-day run that fails for no obvious reason (not that we did this or anything). ↩
We’d love to dig into this more from a research perspective, and get folks help with trying to qualify when this sort of instability arises and in what forms of precision; e.g., will brain-floats solve the problem when it’s available? Can we train in 8-bit precision? Can we prevent this from happening in the first place with an architectural change, without hurting performance? Email us if you have insight, or are looking to tackle this with us! ↩
References
Bommasani, Rishi et al. “On the Opportunities and Risks of Foundation Models.” ArXiv abs/2108.07258 (2021).
Brown, Tom B. et al. “Language Models are Few-Shot Learners.” ArXiv abs/2005.14165 (2020).
Kim, Boseop et al. “What Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-scale Korean Generative Pretrained Transformers.” ArXiv abs/2109.04650 (2021).
Raffel, Colin et al. “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.” JMLR (2020).
Xue, Linting et al. “mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer.” NAACL (2021).
Pineau, Joelle et al. “Improving Reproducibility in Machine Learning Research (A Report from the NeurIPS 2019 Reproducibility Program).” ArXiv abs/2003.12206 (2020).
Gao, Leo et al. “The Pile: An 800GB Dataset of Diverse Text for Language Modeling.” ArXiv abs/2101.00027 (2021).
Zellers, Rowan et al. “Defending Against Neural Fake News.” NeurIPS (2019).
Li, Zhuohan et al. “Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers.” ICML (2020).
Shoeybi, Mohammad et al. “Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism.” ArXiv abs/1909.08053 (2019).
Birhane, Abeba et al. “The Values Encoded in Machine Learning Research.” ArXiv abs/2106.15590 (2021).
Mandeep Baines, et al. “FairScale: A general purpose modular PyTorch library for high performance and large scale training.” https://github.com/facebookresearch/fairscale. (2021).
Rasley, Jeff et al. “DeepSpeed: System Optimizations Enable Training Deep Learning Models with Over 100 Billion Parameters.” Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (2020).
Rajbhandari, Samyam et al. “ZeRO: Memory Optimization Towards Training A Trillion Parameter Models.” SC (2020).
Narayanan, Deepak et al. “Memory-Efficient Pipeline-Parallel DNN Training.” ICML (2021).
Liu, Liyuan et al. “Understanding the Difficulty of Training Transformers.” ArXiv abs/2004.08249 (2020).
Vaswani, Ashish et al. “Attention is All you Need.” ArXiv abs/1706.03762 (2017).
Lipton, Zachary Chase and Jacob Steinhardt. “Troubling Trends in Machine Learning Scholarship.” Queue 17 (2019): 45 - 77.
Dodge, Jesse et al. “Show Your Work: Improved Reporting of Experimental Results.” ArXiv abs/1909.03004 (2019).