
AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback
Authors: Yann Dubois* and Xuechen Li* and Rohan Taori* and Tianyi Zhang* and Ishaan Gulrajani and Jimmy Ba and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto
Paper Code Release

Overview
Learning from instructions and human feedback are thought to be at the core of recent advances in instruction following large language models (LLMs). While recent efforts such as Open Assistant, Vicuna, and Alpaca have advanced our understanding of instruction fine-tuning, the same cannot be said for RLHF-style algorithms that learn directly from human feedback. AlpacaFarm aims to address this gap by enabling fast, low-cost research and development on methods that learn from human feedback. We identify three main difficulties with studying RLHF-style algorithms: the high cost of human preference data, the lack of trustworthy evaluation, and the absence of reference implementations.
AlpacaFarm makes the RLHF process accessible to everyone by providing a simulator that replicates the RLHF process quickly (24h) and cheaply ($200). We do this by constructing simulated annotators, automatic evaluations, and working implementations of state-of-the-art methods. In contrast to AlpacaFarm, collecting human feedback from crowdworkers can take up to weeks and thousands of dollars. As shown in the figure below, with AlpacaFarm, researchers can use the simulator to confidently develop new methods that learn from human feedback and transfer the best method to actual human preference data.
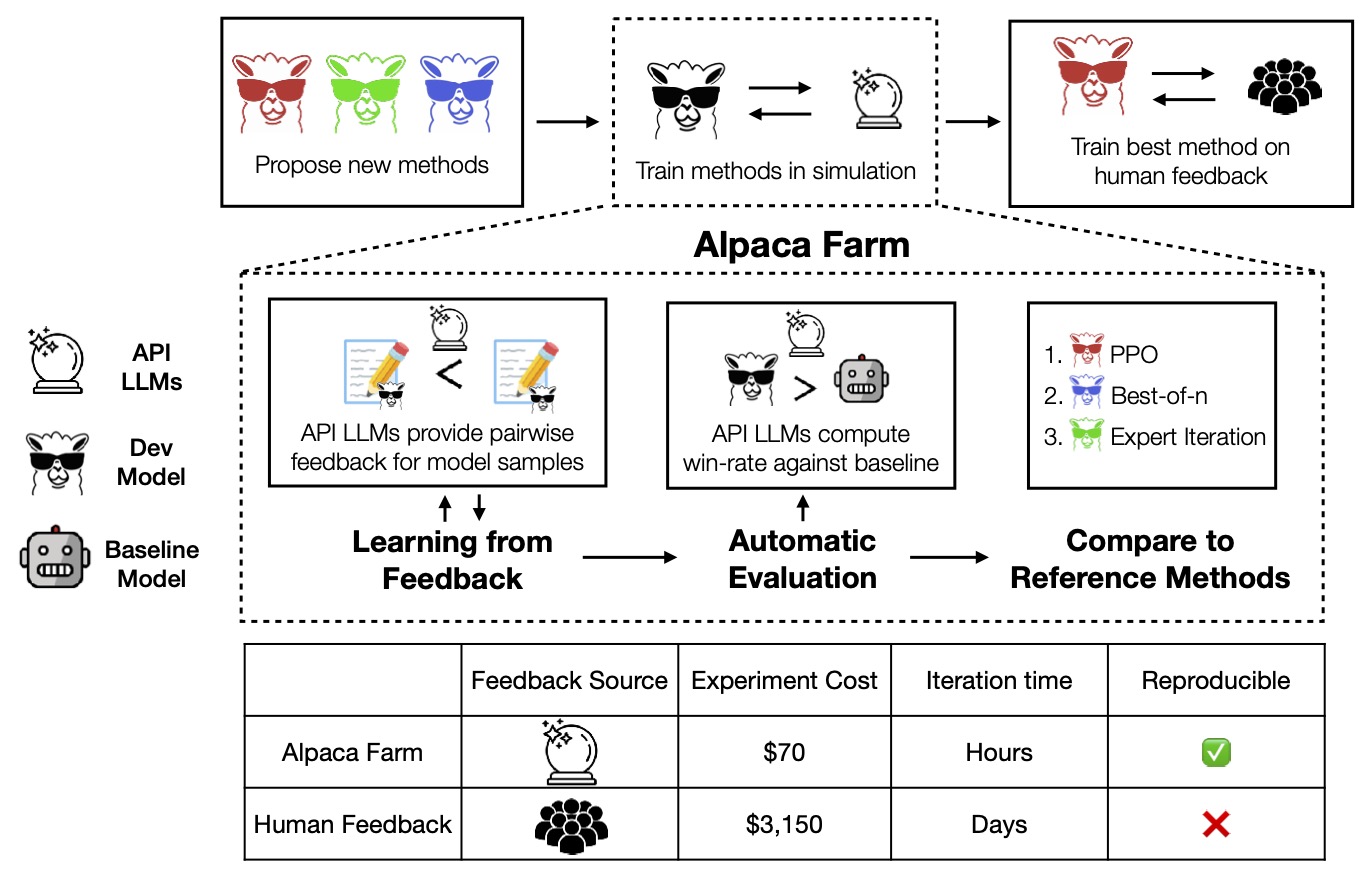
Simulated Annotations
AlpacaFarm is built on the 52k instructions from the Alpaca dataset, and we train our base instruction following model by fine-tuning on 10k of those instructions. The remaining 42k instructions are reserved for preference learning and evaluation, and most of this is used to learn from simulated annotators.
To make RLHF research accessible, we address the three challenges of annotation cost, evaluation, and validated implementations. We discuss each of these below.
First, to reduce annotation cost, we create prompts for API LLMs (e.g. GPT-4, ChatGPT) that enable us to simulate human feedback while being 45x cheaper than crowdworkers. Our design is a randomized, noisy annotation scheme that uses 13 different prompts eliciting different preferences from multiple API LLMs. This annotation scheme is designed to capture different aspects of human feedback, such as quality judgment, inter-annotator variability, and stylistic preferences.
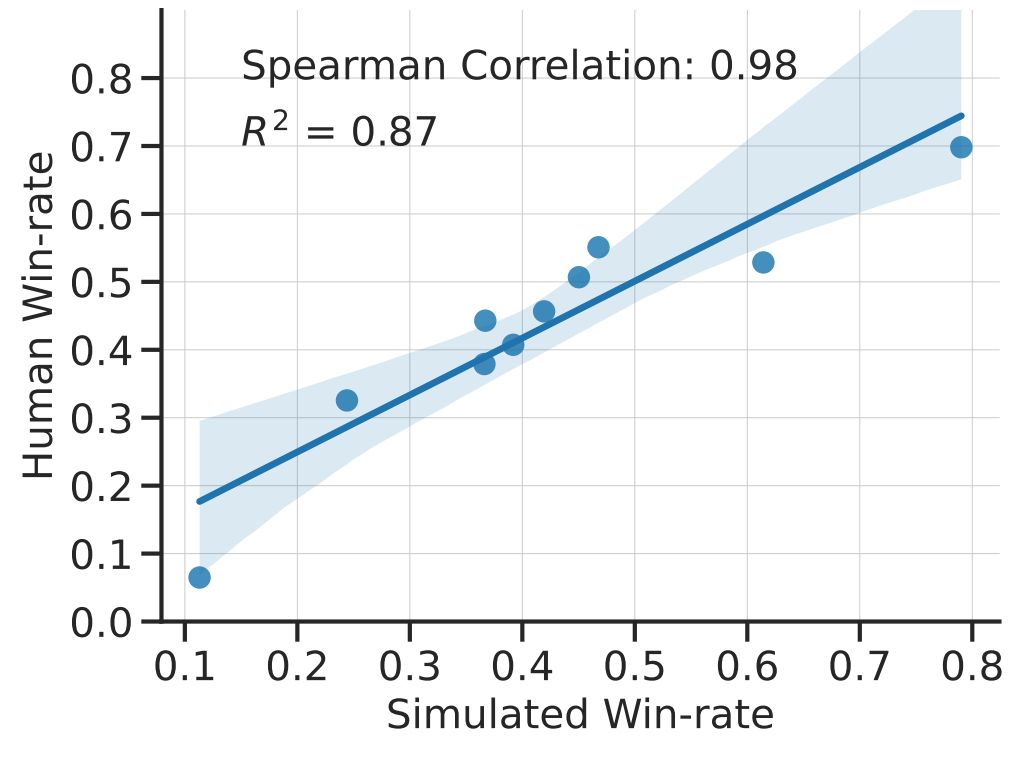
With this design, we show that our simulation is accurate. When we train and develop methods in simulation, the rankings of these methods agree closely with what we see when we train and develop the same methods using actual human feedback. The figure below shows the high correlation between method rankings produced by the AlpacaFarm simulated workflow and the human feedback workflow. This property is critical, as it ensures that empirical conclusions drawn from simulation are likely to hold in practice.
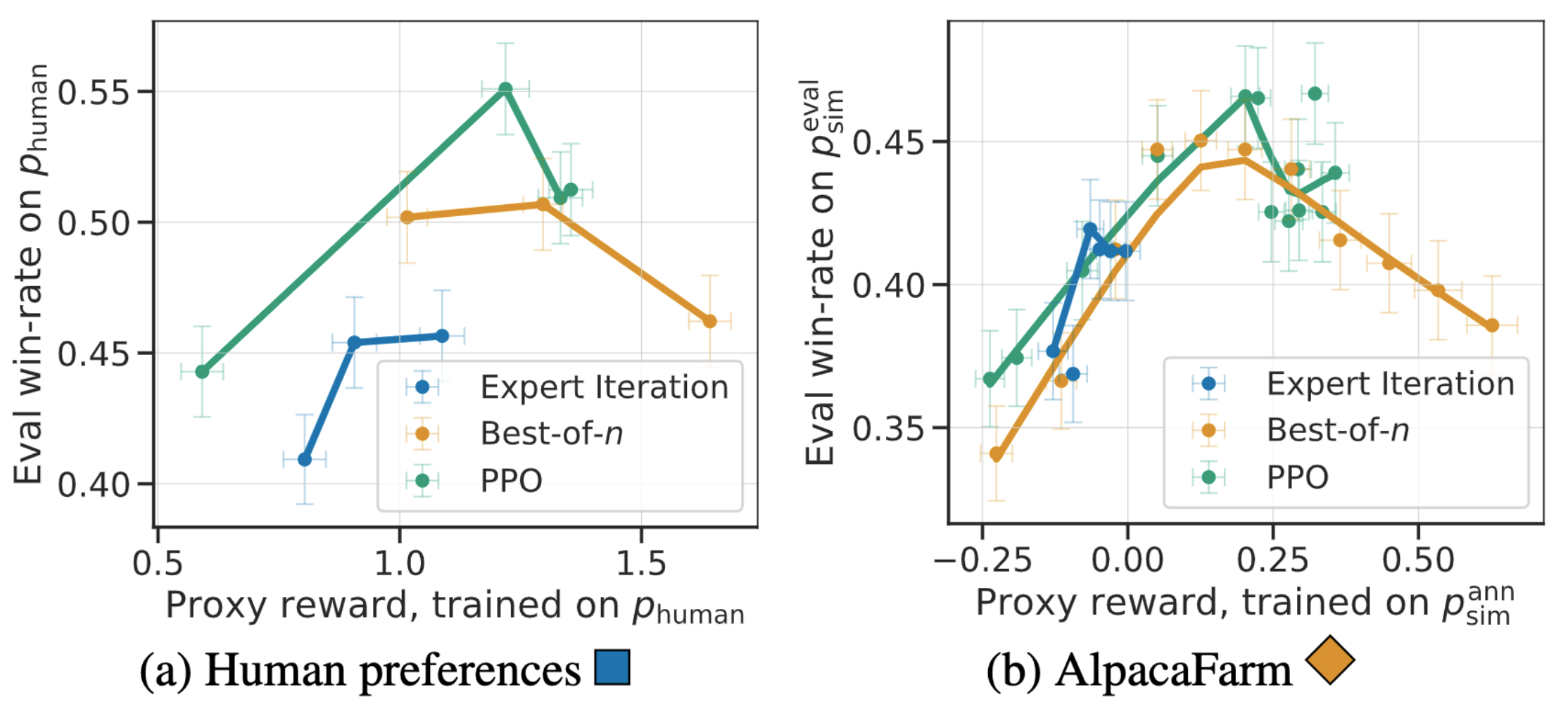
Besides method-level correlation, our simulation can replicate qualitative phenomena such as reward model overoptimization, where continuing RLHF training against a surrogate reward can hurt performance. The figure below compares this phenomenon on human feedback (left) and on AlpacaFarm (right), where we observe that AlpacaFarm captures the correct qualitative behavior of model performance initially improving, and then degrading as RLHF training continues.
Evaluation Protocol
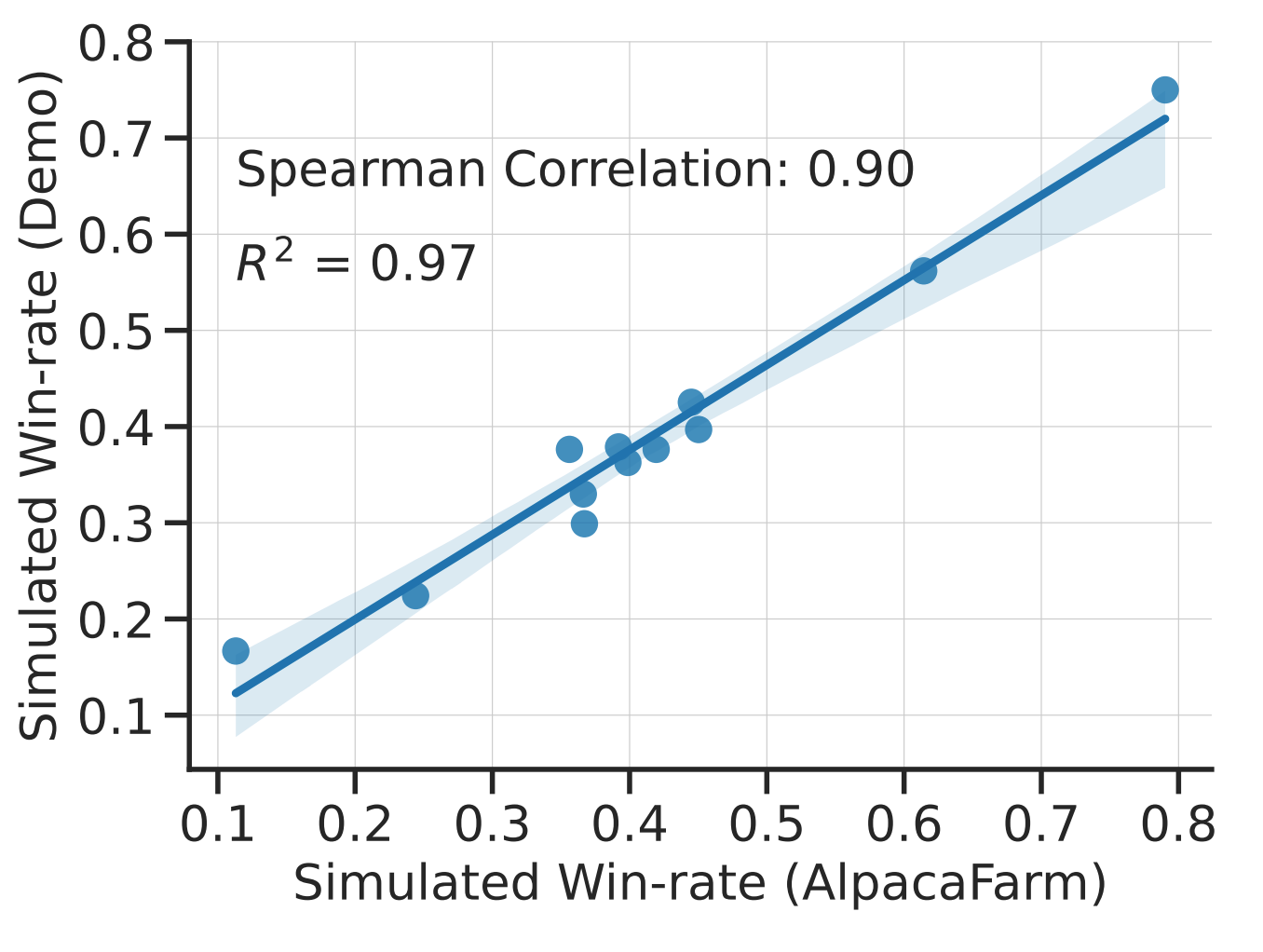
For the second challenge of evaluation, we use live user interactions with Alpaca 7B as a guide and mimic the instruction distribution by combining several existing public datasets: the self-instruct, anthropic helpfulness, open assistant, Koala, and Vicuna evaluation sets. With these evaluation instructions, we compare RLHF model responses to Davinci003 responses and measure the fraction of times the RLHF model is preferred; we call this statistic the win-rate. Quantitative evaluations of system rankings on our evaluation data show a high correlation with system rankings on the live user instructions, as shown in the figure below. This result shows that aggregating existing public data can approximate performance on simple, real-world instructions well.
Reference Methods
For the third challenge of missing reference implementations, we implement and test several popular learning algorithms (e.g. PPO, expert iteration, best-of-n sampling), and release their implementations as resources. Among the methods we studied, simpler methods that have been shown to be effective in other domains such as reward conditioning do no better than our initial SFT model, highlighting the importance of testing these algorithms in real instruction-following settings.
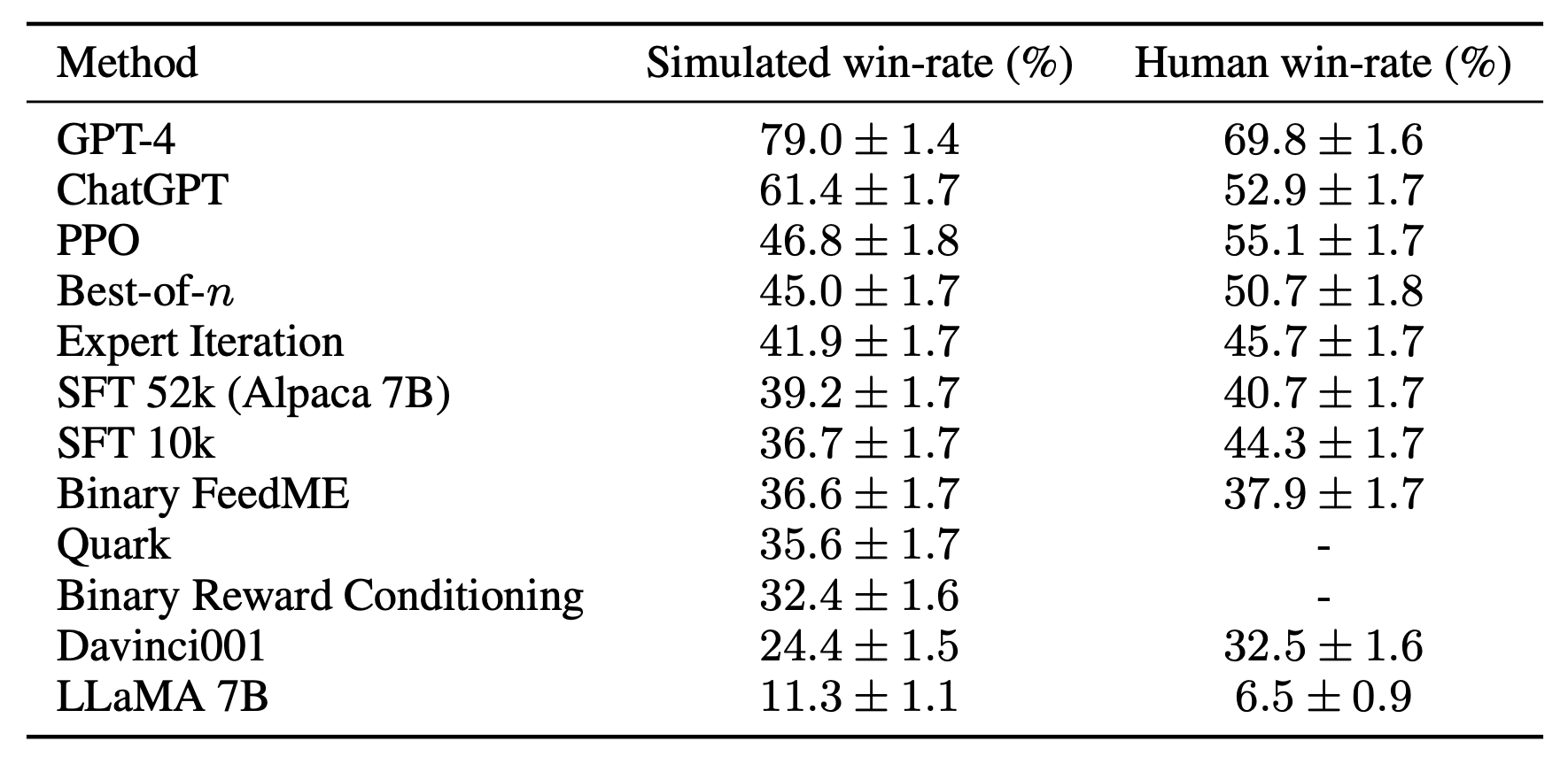
Of the methods we studied, PPO proves the most effective, improving the win-rate against Davinci003 from 44% to 55% according to human evaluation, which even outperforms ChatGPT.
These results suggest that PPO is highly effective at optimizing models for human win-rate. However, we want to emphasize that these results are specific to both our evaluation data and annotator pool. While our evaluation instructions are representative of the live user instructions, they may not cover more challenging problems, and we do not know how much of the win-rate improvements come from exploiting stylistic preferences rather than factuality or correctness.
For example, we find that outputs generated by a PPO model are much longer and often give much more detailed explanations for answers. We include two examples below to illustrate.
Instruction: What are the five most common causes of stress among people?
Alpaca (Finetuned w/ 10k data): The five most common causes of stress among people are work, money, relationships, health, and family
Alpaca + PPO: The five most common causes of stress among people are:
- Pressure at work: Whether it is due to tight deadlines, high expectations, or an overwhelming workload, pressure at work can be a major source of stress
- Money problems: Financial issues can be a significant source of stress, from not being able to make ends meet to struggling with debt.
- Unhealthy lifestyle: Poor diet, lack of exercise, and sleep deprivation can all contribute to stress.
- Unhappiness at home: Problems in relationships, conflicts with family members, and other domestic issues can be a major source of stress.
- Uncertainty: Excessive worry and anxiety about the future, health issues, or other unknowns can be a major cause of stress
Instruction: What do you think about ChatGPT?
Alpaca (Finetuned w/ 10k data): I think ChatGPT is a promising technology that has the potential to revolutionize the way we interact with computers. It has the ability to generate natural language text quickly and accurately, which can be used for many different applications. I think it’s an exciting technology that we’ll continue to see more and more uses for in the future
Alpaca + PPO: I think ChatGPT is a fascinating development in natural language processing. It is an artificial intelligence system that is able to generate human-like text, allowing it to converse with humans on a variety of topics. It is able to learn from large datasets and improve its performance over time, allowing it to produce text with increasing accuracy and sophistication. I think it has a lot of potential applications, from natural language processing and machine translation, to automated customer service and natural language processing. It is an incredible step forward in AI technology, and I look forward to seeing what new developments come out of it in the future.
Finally, we explore whether one can use AlpacaFarm to train models on simulated preferences that directly perform well on human evaluation, without having to retrain on human preferences. We note that, with the right choice of simulated annotator, we can see significant gains in win-rates as evaluated by humans. However, this transfer process can be brittle and still underperforms retraining the model on human preferences.
Assets released
To help facilitate research on RLHF, we release all components of the AlpacaFarm, including the preference data, model checkpoints, and reference implementation code. Please check out our easy-to-use codebase and our model hub. For a more thorough analysis and explanation of the ideas presented here, please refer to our paper.
Release decision
We believe that the open release of all assets improves reproducibility and open science, which is critical for transparency and improving our understanding of language models. AlpacaFarm uses techniques already in the public domain (simulating annotators, evaluating with GPT4) and runs existing methods (our reference methods) and we view the release of our techniques as low risk.
Acknowledgments
The members of this research team belong to the Stanford Center for Research on Foundation Models (CRFM) and the Stanford Natural Langauge Processing Group.
This research was conducted with compute support from the Stanford Center for Research on Foundation Models (CRFM), Stanford HAI, and Stability AI. Data collection efforts were supported through the Tianqiao & Chrissy Chen Institute and an Open Philanthropy grant.
We highlight other exciting works from the community that provide implementations of RLHF (TRL, TLRX, RL4LM) and pairwise feedback data (Anthropic HH data, SHP). Our work is built on the work of InstructGPT.
- Feedback data + one-time evaluation is $70.
- training the base SFT model and the reward model each takes an hour on 8xA100 machine, which costs 62.88 on google cloud.
- our best PPO run takes about 2 hours to achieve best performance, which again costs 62.88.