
Do Foundation Model Providers Comply with the Draft EU AI Act?
Authors: Rishi Bommasani and Kevin Klyman and Daniel Zhang and Percy Liang
Requirements Rubrics Grades GitHub

Foundation models like ChatGPT are transforming society with their remarkable capabilities, serious risks, rapid deployment, unprecedented adoption, and unending controversy. Simultaneously, the European Union (EU) is finalizing its AI Act as the world’s first comprehensive regulation to govern AI, and just yesterday the European Parliament adopted a draft of the Act by a vote of 499 in favor, 28 against, and 93 abstentions. The Act includes explicit obligations for foundation model providers like OpenAI and Google.
In this post, we evaluate whether major foundation model providers currently comply with these draft requirements and find that they largely do not. Foundation model providers rarely disclose adequate information regarding the data, compute, and deployment of their models as well as the key characteristics of the models themselves. In particular, foundation model providers generally do not comply with draft requirements to describe the use of copyrighted training data, the hardware used and emissions produced in training, and how they evaluate and test models. As a result, we recommend that policymakers prioritize transparency, informed by the AI Act’s requirements. Our assessment demonstrates that it is currently feasible for foundation model providers to comply with the AI Act, and that disclosure related to foundation models’ development, use, and performance would improve transparency in the entire ecosystem.
Motivation
Foundation models are at the center of global discourse on AI: the emerging technological paradigm has concrete and growing impact on the economy, policy, and society. In parallel, the EU AI Act is the most important regulatory initiative on AI in the world today. The Act will not only impose requirements for AI in the EU, a population of 450 million people, but also set precedent for AI regulation around the world (the Brussels effect). Policymakers across the globe are already drawing inspiration from the AI Act, and multinational companies may change their global practices to maintain a single AI development process. How we regulate foundation models will structure the broader digital supply chain and shape the technology’s societal impact.
Our assessment establishes the facts about the status quo and motivates future intervention.
- Status quo. What is the current conduct of foundation model providers? And, as a result, how will the EU AI Act (if enacted, obeyed, and enforced) change the status quo? We specifically focus on requirements where providers fall short at present.
- Future intervention. For EU policymakers, where is the AI Act underspecified and where is it insufficient with respect to foundation models? For global policymakers, how should their priorities change based on our findings? And for foundation model providers, how should their business practices evolve to be more responsible? Overall, our research underscores that transparency should be the first priority to hold foundation model providers accountable.
Methodology
Below is a summary of our approach, including all relevant details in the referenced documents.
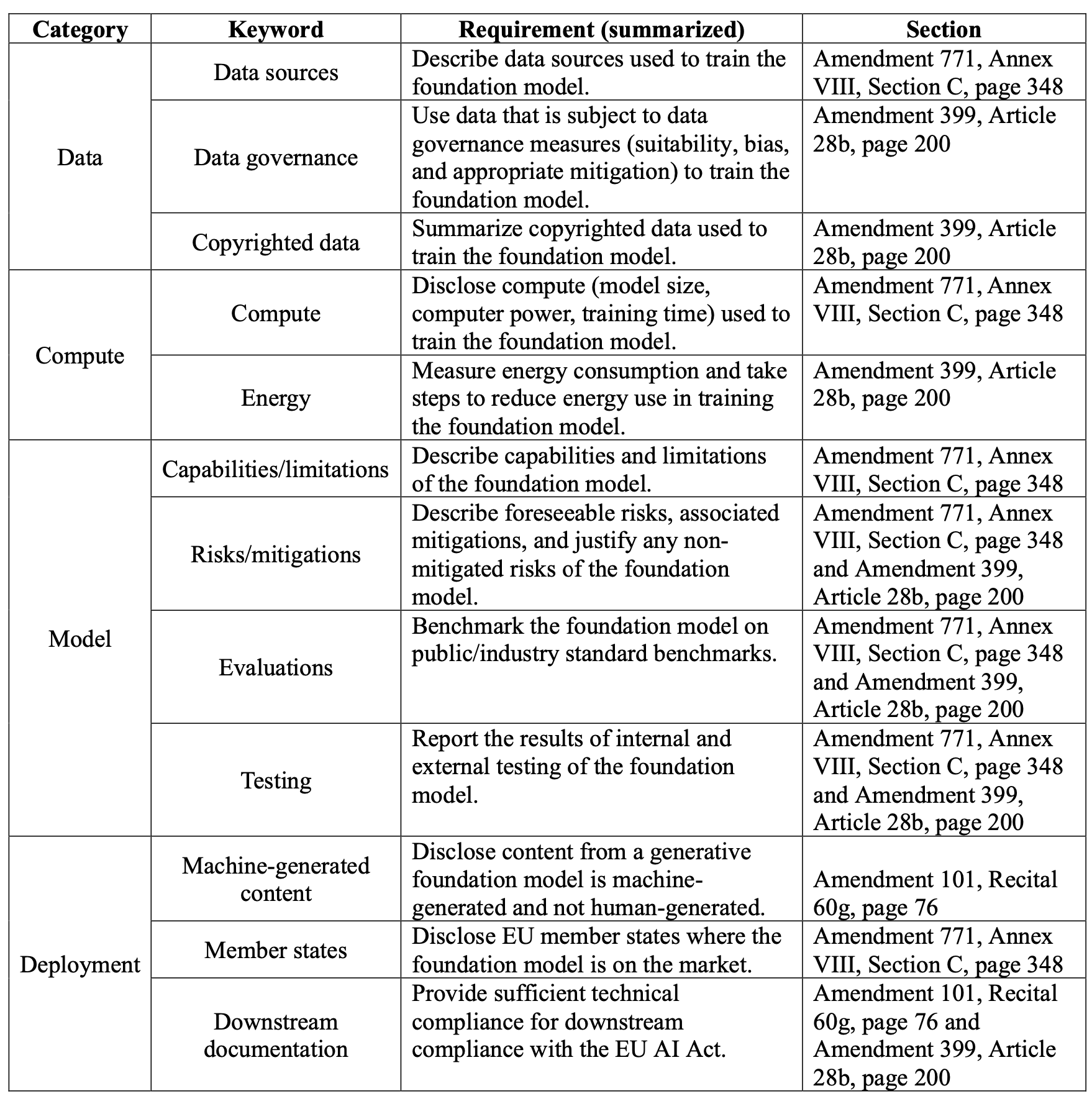
- We extract 22 requirements directed towards foundation model providers from the European Parliament’s version of the Act. We select 12 of the 22 requirements to assess—these requirements are able to be meaningfully evaluated using public information.1
- We categorize the 12 requirements as pertaining to (i) data resources (3), (ii) compute resources (2), (iii) the model itself (4), or (iv) deployment practices (3). Many of these requirements center on transparency: for example, disclosure of what data was used to train the foundation model, how the model performs on standard benchmarks, and where it is deployed. We summarize the 12 requirements in the table above.
- We design a 5-point rubric for each of the 12 requirements. While the Act states high-level obligations for foundation model providers, it does not make precise how these obligations should be interpreted or enforced. Our rubrics come from our expertise on the societal impact of foundation models. These rubrics can directly inform statutory interpretation or standards, including in areas where the Act’s language is especially unclear.
- We assess the compliance of 10 foundation model providers—and their flagship foundation models—with 12 of the Act’s requirements for foundation models based on our rubrics. The two lead authors independently scored all the providers for all requirements with substantial inter-annotator agreement of Cohen’s Kappa = 0.74. We merge scores through panel discussion with all authors involved in this work. While comprehensive assessment of compliance with these requirements will require additional guidance from the EU, our research on providers’ current practices will play a valuable role when regulators ultimately assess compliance.
Findings
We present the final scores in the above figure with the justification for every grade made available. Our results demonstrate a striking range in compliance across model providers: some providers score less than 25% (AI21 Labs, Aleph Alpha, Anthropic) and only one provider scores at least 75% (Hugging Face/BigScience) at present. Even for the highest-scoring providers, there is still significant margin for improvement. This confirms that the Act (if enacted, obeyed, and enforced) would yield significant change to the ecosystem, making substantial progress towards more transparency and accountability.
Persistent challenges. We see four areas where many organizations receive poor scores (generally 0 or 1 out of 4). They are (i) copyrighted data, (ii) compute/energy, (iii) risk mitigation, and (iv) evaluation/testing. These speak to established themes in the scientific literature:
- Unclear liability due to copyright. Few providers disclose any information about the copyright status of training data. Many foundation models are trained on data that is curated from the Internet, of which a sizable fraction is likely copyrighted. The legal validity of training on this data as a matter of fair use, especially for data with specific licenses, and of reproducing this data, remains unclear.
- Uneven reporting of energy use. Foundation model providers inconsistently report energy usage, emissions, their strategies for measurement of emissions, and any measures taken to mitigate emissions. How to measure the energy required to train foundation models is contentious (Strubell et al., 2019; Patterson et al., 2021). Regardless, the reporting of these costs proves to be unreliable, in spite of many efforts that have built tools to facilitate such reporting (Lacoste et al., 2019; Henderson et al., 2020; Luccioni et al., 2023).
- Inadequate disclosure of risk mitigation/non-mitigation. The risk landscape for foundation models is immense, spanning many forms of malicious use, unintentional harm, and structural or systemic risk(Bender et al., 2021; Bommasani et al., 2021; Weidinger et al., 2021). While many foundation model providers enumerate risks, relatively few disclose the mitigations they implement and the efficacy of these mitigations. The Act also requires that providers describe “non-mitigated risks with an explanation on the reason why they cannot be mitigated”, which none of the providers we assess do.
- Absence of evaluation standards/auditing ecosystem. Foundation model providers rarely measure models’ performance in terms of intentional harms such as malicious use or factors such as robustness and calibration. Many in the community have called for more evaluations, but standards for foundation model evaluation (especially beyond language models) remain a work-in-progress (Liang et al., 2022, Bommasani et al., 2023, Solaiman et al., 2023). In the U.S., the mandate for NIST to create AI testbeds under Section 10232 of the CHIPS and Science Act identifies one path towards such standards.
Open vs restricted/closed models. We find a clear dichotomy in compliance as a function of release strategy, or the extent to which foundation model providers make their models publicly available. At present, foundation model providers adopt a variety of release strategies, with no established norms. While release strategies are not binary and exist on a spectrum, for simplicity we consider broadly open releases (e.g. EleutherAI’s GPT-NeoX, Hugging Face/BigScience’s BLOOM, Meta’s LLaMA) vs restricted/closed releases (e.g. Google’s PaLM 2, OpenAI’s GPT-4, Anthropic’s Claude). Open releases generally achieve strong scores on resource disclosure requirements (both data and compute), with EleutherAI receiving 19/20 for these categories. However, such open releases make it challenging to monitor or control deployment, with more restricted/closed releases leading to better scores on deployment-related requirements. For instance, Google’s PaLM 2 receives 11/12 for deployment. We emphasize that EU policymakers should consider strengthening deployment requirements for entities that bring foundation models to market to ensure there is sufficient accountability across the digital supply chain.
The relationship between release and area-specific compliance to some extent aligns with our intuitions. Open releases are often conducted by organizations that emphasize transparency, leading to a similar commitment to disclosing the resources required to build their foundation models. Restricted or closed releases, by contrast, often coincide with models that power the provider’s flagship products and services, meaning the resources underlying the model may be seen as a competitive advantage (e.g. data decomposition) or a liability (e.g. copyrighted data). In addition, open-sourcing a model makes it much more difficult to monitor or influence downstream use, whereas APIs or developer-mediated access provide easier means for structured access.
Overall feasibility of compliance. No foundation model provider achieves a perfect score, with ample room for improvement in most cases. Therefore, we consider whether it is currently feasible for organizations to fully comply with all requirements. While we believe that with sufficient incentives (e.g. fines for noncompliance) companies will change their conduct, even in the absence of strong regulatory pressure, many providers could reach total scores in the high 30s or 40s through meaningful, but plausible, changes. To be concrete, the entry-wise maximum across OpenAI and Hugging Face/BigScience is 42 (almost 90% compliance). We conclude that enforcing these 12 requirements in the Act would bring substantive change while remaining within reach for providers.
Releases of foundation models have generally become less transparent, as evidenced by major releases in recent months. The reports for OpenAI’s GPT-4 and Google’s PaLM 2 openly state that they do not report many relevant aspects about data and compute. The GPT-4 paper reads “Given both the competitive landscape and the safety implications of large-scale models like GPT-4, this report contains no further details about the architecture (including model size), hardware, training compute, dataset construction, training method, or similar.”
We believe sufficient transparency to satisfy the Act’s requirements related to data, compute and other factors should be commercially feasible if foundation model providers collectively take action as the result of industry standards or regulation. We see no significant barriers that would prevent every provider from improving how it discusses limitations and risks as well as reporting on standard benchmarks. Although open-sourcing may make aspects of deployment disclosure challenging, feasible improvements in disclosure of machine-generated content or availability of downstream documentation abound. While progress in each of these areas requires some work, in many cases we believe this work is minimal relative to building and providing the foundation model and should be seen as a prerequisite for being a responsible and reputable model provider.
Recommendations
We direct our recommendations to three parties: (i) EU policymakers working on the EU AI Act, (ii) global policymakers working on AI policy, and (iii) foundation model providers operating across the ecosystem.
EU policymakers.
- The implementation of the EU AI Act and technical standards to follow should specify areas of the Act that are underspecified. Given our expertise in evaluations, we emphasize the importance of specifying which dimensions of performance are necessary to disclose to comply with the mandate for a “description of the model’s performance”. We advocate that several factors such as accuracy, robustness, fairness, and efficiency be considered necessary for compliance (the NIST AI Risk Management Framework provides a similar list).
- The EU AI Act should consider additional critical factors to ensure adequate transparency and accountability of foundation model providers, including the disclosure of usage patterns: such requirements would mirror transparency reporting for online platforms, the lack of which has been a chronic inhibitor for effective platform policy. We need to understand how foundation models are used (e.g. for providing medical advice, preparing legal documents) to hold their providers to account. We encourage policymakers to consider making these requirements apply only to the most influential foundation model providers, directly mirroring how the EU’s Digital Services Act places special requirements on Very Large Online Platforms to avoid overburdening smaller companies.
- For effective enforcement of the EU AI Act to change the conduct of the powerful organizations that build foundation models, the EU must make requisite technical resources and talent available to enforcement agencies, especially given the broader AI auditing ecosystem envisioned in the Act. Our assessment process made clear that technical expertise on foundation models is necessary to understand this complex ecosystem.
Global policymakers.
- Transparency should be the first priority for policy efforts: it is an essential precondition for rigorous science, sustained innovation, accountable technology, and effective regulation. Our work shows transparency is uneven at present, and an area where the EU AI Act will bring clear change that policy elsewhere should match. The history of social media regulation provides clear lessons for policymakers—failing to ensure sufficient platform transparency led to many of the harms of social media; we should not reproduce these failures for the next transformational technology in foundation models.
- Disclosure of copyrighted training data is the area where we find foundation model providers achieve the worst compliance. Legislators, regulators and courts should clarify how copyright relates to (i) the training procedure, including the conditions under which copyright or licenses must be respected during training as well as the measures model providers should take to reduce the risk of copyright infringement and (ii) the output of generative models, including the conditions under which machine-generated content infringes on the rights of content creators in the same market.
Foundation model providers.
- Our work indicates where each foundation model provider can improve. We highlight many steps that are low-hanging fruit, such as improving the documentation made available to downstream developers that build on foundation models. In various cases, some providers score worse than others with similar release strategies (e.g. different providers that deploy their foundation models via an API). Therefore, providers can and should improve compliance by emulating similar providers that are best-in-class.
- Foundation model providers should work towards industry standards that will help the overall ecosystem become more transparent and accountable. The standards-setting process should involve stakeholders beyond foundation model providers with specific attention towards parties that can better represent the public interest like academia and civil society.
Limitations
While we offer expertise on foundation models, our reading of the draft law is not genuine statutory interpretation, though it could inform such interpretation (especially where the law is unclear). The AI Act remains under discussion and will be finalized during the upcoming trilogue between the EU Commission, Council, and Parliament. Foundation model providers also have requirements under provisions of the AI Act that do not address only foundation models, such as when their foundation models are integrated into high-risk AI systems. Therefore, our assessments might diverge from foundation models providers’ compliance with the final version of the AI Act. Given that our assessment is based on, and limited by, publicly available information, we encourage foundation model providers to provide feedback to us and respond to these scores.
Conclusion
We find that foundation model providers unevenly comply with the stated requirements of the draft EU AI Act. Enacting and enforcing the EU AI Act will bring about significant positive change in the foundation model ecosystem. Foundation model providers’ compliance with requirements regarding copyright, energy, risk, and evaluation is especially poor, indicating areas where model providers can improve. Our assessment shows sharp divides along the boundary of open vs. closed releases: we believe that all providers can feasibly improve their conduct, independent of where they fall along this spectrum. Overall, our analysis speaks to a broader trend of waning transparency: providers should take action to collectively set industry standards that improve transparency, and policymakers should take action to ensure adequate transparency underlies this general-purpose technology. This work is just the start of a broader initiative at the Center for Research on Foundation Models to directly assess and improve the transparency of foundation model providers, complementing our efforts on holistic evaluation, ecosystem documentation, norms development, policy briefs, and policy recommendations.
Acknowledgments
We thank Alex Engler, Arvind Narayanan, Ashwin Ramaswami, Dan Ho, Irene Solaiman, Marietje Schaake, Peter Cihon, and Sayash Kapoor for feedback on this effort. We thank Alex Engler, Arvind Narayanan, Ashwin Ramaswami, Aviv Ovadya, Conor Griffin, Dan Ho, Iason Gabriel, Irene Solaiman, Joslyn Barnhart, Markus Anderljung, Sayash Kapoor, Seliem El-Sayed, Seth Lazar, Stella Bidermann, Toby Shevlane, and Zak Rogoff for broader discussions on this topic. We thank Madeleine Wright for designing the graphics.
@misc{bommasani2023eu-ai-act,
author = {Rishi Bommasani and Kevin Klyman and Daniel Zhang and Percy Liang},
title = {Do Foundation Model Providers Comply with the EU AI Act?},
url = {https://crfm.stanford.edu/2023/06/15/eu-ai-act.html},
year = {2023}
}
-
We acknowledge that the 12 selected requirements do not include a few of the most substantive requirements (which we cannot meaningfully assess from our vantage point, largely due to a lack of adequate transparency and established standards). Therefore, our scores underestimate the difficulty of compliance with all 22 requirements. Providers that score poorly will have even more work to do to comply with the full set of 22 requirements. ↩