
Anticipatory Music Transformer: A Controllable Infilling Model for Music
Authors: John Thickstun and David Hall and Chris Donahue and Percy Liang
Paper Code Release Model Release Model Card Colab Notebook
Correspondence to: jthickstun@cs.stanford.edu
- Input
- Output


Hover (click on mobile) to see the generated completions.
The Anticipatory Music Transformer is a generative model of symbolic music. We can control this model by writing parts of a musical composition, and asking the model to fill in the rest. For example, suppose you wrote a melody: you can ask the model to suggest accompaniments to this melody. Or suppose you wrote a complete composition and are unsatisfied with a particular section: you can ask the model to suggest alternative variations for this section. These are examples of infilling control: the Anticipatory Music Transformer generates (i.e., infills) completed musical compositions, given an incomplete composition as input (see Figure 1).
People value agency and control over creative collaborations with generative AI; we want to build models that promote interactive, human-centered engagements. The Anticipatory Music Transformer facilitates co-creation of music via infilling operations. Infilling gives a composer fine-grained control over this collaboration, choosing what to write themselves and what to delegate to AI. Infilling control also facilitates an interactive co-creation process, whereby the composer iteratively queries the model and keeps fragments of the generated music that they like while discarding the rest.
The Anticipatory Music Transformer models symbolic music rather than musical audio. We model symbolic music because we hope to build interactive tools for composers, analogous to a writing assistant. For the audio examples below, we synthesize artificial performances of symbolic music. This mechanical synthesis generates audio with a particular quality reminiscent of 90's video game music. We are enthusiastic about collaborating with musicians and electronic music producers to create more expressive and sonically rich performances: if you are interested in artistic collaborations, please reach out!
- Tonal controls
- Percussive controls
- Tonal completion
- Percussive completion
Using infilling control, we can generate and revise variations of the output of an Anticipatory Music Transformer to suit our preferences. In Example 1, we show two different accompaniments generated by the model (visualized in purple and orange) given a generated melody and a brief vamp as input (visualized in blue and green). After choosing to accept the first accompaniment (option 1) we may continue to revise this composition. For example, we can delete a span of notes from the composition, and query the Anticipatory Music Transformer to offer alternative infilling revisions for this missing span. This interaction pattern is exhibited in Example 2.
- Tonal controls
- Percussive controls
- Tonal completion
- Percussive completion
We release the 360M parameter Anticipatory Music Transformer used to create the examples on this page. This model was trained for 800k steps on the Lakh MIDI dataset. We also release code for training and querying the model. This code is a crude interface for interacting with the Anticipatory Music Transformer: we encourage the community to integrate this model into more standard music sequencing workflows such as Ableton or Logic. Please reach out if we are able to help with these integrations.
Foundation Models for Music
The Anticipatory Music Transformer is built using the generative pretrained Transformer architecture (GPT) that powers language models like GPT-4 and tools like ChatGPT. Analogous to language models that are trained to predict the next word in a sentence, previous GPT-powered music models--including Google's Music Transformer and OpenAI's MuseNet--are trained to predict the next note in a sequence given the past. These models linearly generate a composition from start to finish. In contrast, the human process of music composition is iterative and non-linear: a composer will sketch, edit, go back, and revise a draft many times.
A foundation model for music should support the human composition process. In contrast to standard GPT-based models that generate music from start to finish, the Anticipatory Music Transformer is trained to infill parts of a pre-existing draft composition. We believe that infilling control complements the human composition and editing process. The infilling capabilities of the Anticipatory Music Transformer are made possible by a modeling principle that we call anticipation. Whereas standard GPT-based models are trained to predict the next note given the past, anticipatory models are trained to predict the future given both the past and foreknowledge of certain upcoming notes in the future. We say that the anticipatory model anticipates these upcoming notes. See the paper for a technical description of anticipation.
Like sequence-to-sequence modeling (Seq2Seq) anticipation combines a pair of input and output sequences into a single training sequence. Whereas Seq2Seq prepends the input sequence to the output sequence, anticipation interleaves inputs with outputs, so that an input note at time t is located close to outputs near time t in the combined sequence. This preserves locality in the training sequence, an important inductive bias for many models. Crucially, we show in the paper that—to be able to condition on the inputs of an anticipatory model—the inputs must appear following stopping times in the ouput sequence. This property is not satisfied by natural interleaving strategies (e.g., sort-ordering) which motivates a more subtle definition of anticipation.
Infilling makes the Anticipatory Music Transformer more controllable than previous generative models of music. Music infilling control is analogous to the inpainting capabilities of generative image models like DALL·E and Stable Diffusion. In contrast to these image models, the Anticipatory Music Transformer does not use language to control the model's outputs. Whereas language is an expressive medium for describing visual imagery, colloquial language is often a poor tool for expressing musical ideas: writing about music is like dancing about architecture. Instead of providing a language interface, we focus on infilling capabilities as an interaction mechanism for controlling the Anticipatory Music Transformer.
Interactive Control
We control the Anticipatory Music Transformer with asynchronous control inputs (e.g., a melody). These controls are asynchronous because they can appear at different times than the generated notes (e.g., an accompaniment to the melody). In addition to control inputs, we can exercise editorial control by choosing to accept, reject, or revise the generated notes proposed by the model. Accepted notes are appended to the note history, becoming feedback to subsequent generation. We can think of the Anticipatory Music Transformer as a non-linear, asynchronous feedback controller. An example of an interactive control flow for symbolic music generation is illustrated by Figure 2.
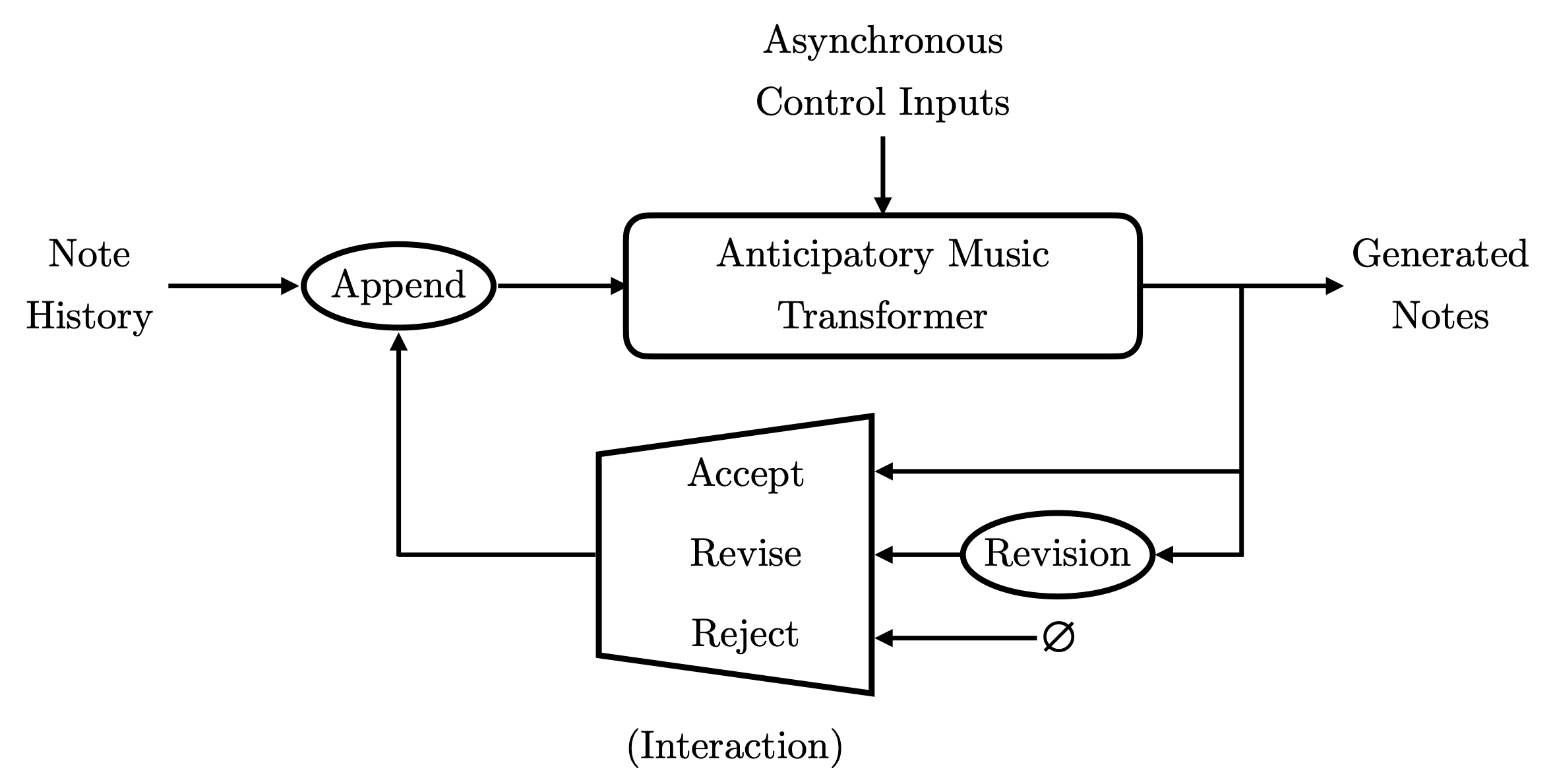
The accompaniments in Example 3 are created using this interactive feedback loop, using a melody as the control inputs. We interact with the model by incrementally generating a short sequence of notes (2-5 seconds at a time) and choosing whether to accept or reject this proposed continuation of the music. We did not manually revise the model's outputs to create the music in Example 3. Generating music with this incremental, interactive process allows us to control its evolution, steering the Anticipatory Music Transformer in directions that we find musically interesting. Samples from the model generated without human interaction are included at the end of this post.
We sample from the model using nucleus sampling. By default (and for the non-interactive examples at the end of this post) we use Nucleus p=0.95. But for interactive generation, we found it helpful to vary this parameter. Setting high values of p encourages diverse generation: sometimes this creates exciting music, but the results can also be too experimental. Setting low values of p encourages more conservative generation. By adaptively choosing p, we are able to exert further control over the model, adjusting between more exploratory musical ideation (high p) and more conservative resolution of earlier musical ideas. See the Colab notebook for an implementation of this interactive control flow.
- Tonal input
- Percussive input
- Tonal output
- Percussive output
Releasing the Anticipatory Music Transformer
We release the model featured on this page, as well as models trained for the ablation study in Table 1 of the paper. Intermediate training checkpoints (saved every 10k steps) are also available on request. All code and models are released under the Apache License, Version 2.0.
- Paper: the paper describing anticipation, the application of anticipation to implementing and training an Anticipatory Music Transformer, evaluation of these models, and discussion of the potential use and deployment of these models.
- Code: code related to the Anticipatory Music Transformer, including infrastructure for pre-processing anticipatory dataset, sampling from the model, and performing human evaluation. Instructions are also included for training an Anticipatory Music Transformer; the Levanter codebase used to train these models is available separately.
- Model Weights: the final checkpoints for each of the 9 models trained in the paper are hosted by the Stanford CRFM organization on the HuggingFace Hub. Here are links to specific models (Row numbers reference Table 1 of the Anticipatory Music Transformer paper):
- Small Autoregressive - 100k Steps (Row 1) [Interarrival-Time Encoded]
- Small Autoregressive - 100k Steps (Row 2)
- Small Anticipatory - 100k Steps (Row 3)
- Small Autoregressive - 800k Steps (Row 4)
- Small Anticipatory - 800k Steps (Row 5) [Good Model; More Efficient Inference]
- Medium Anticipatory - 100k Steps (Row 6)
- Medium Anticipatory - 200k Steps (Row 7)
- Medium Anticipatory - 800k Steps (Row 8) [Better Model; Best Model Studied in the Paper]
- Large Anticipatory - 100k Steps (Row 9)
- Large Anticipatory - 800k Steps [Best Model; Released March 2024; Uses Additional Training Data]
- Google Colab notebook: an interactive demo of the Anticipatory Music Transformer.
The Lakh MIDI dataset used to train the Anticipatory Music Transformer is licensed under the Creative Commons CC-BY 4.0 terms, which ostensibly allows free redistribution, reuse, remixing, and transformation of its content for any purpose. However, in many cases, the MIDI files contained in this dataset are derivative work, transcribed from source material (e.g., pop music) that is subject to copyright; we presume that the copyright status of Lakh MIDI is more restrictive than its license would suggest. The copyright status of models trained on copyrighted data is an open legal question, and therefore the Apache 2.0 license may not fully reflect the legal status of the Anticipatory Music Transformer.
Generative models are known to memorize parts of their training data. The Anticipatory Music Transformer provide no technical guarantees against reproducing music from the Lakh MIDI training dataset: any music generated by the Anticipatory Music Transformer risks infringing on copyrighted material. Indeed, we observe that the third example of the generated accompaniments is nearly identical to the corresponding human-composed accompaniment; it is likely that a near-duplicate version of this composition appears in the Lakh MIDI training data split and has been memorized. We therefore recommend caution in deployment of these models for commercial activities.
We see many opportunities for generative models to support human creativity and expression. But insofar as these models increase productivity or automate aspects of the creative process, they may also be disruptive for people who make a living creating commercial art and music. See Section 7 of the paper for a more thorough discussion of ethical considerations regarding the deployment of generative models of music. We have worked to construct a model with control capabilities that make it a useful, empowering tool for composers. We welcome feedback on our decision to pursue this line of research; we hope to foster a discussion of how we can steer future research in this area towards methods that serve and support composers and musicians.
Acknowledgments
We thank Jennifer Brennan, Andy Chen, and Josh Gardner for feedback on this blog post.
The members of this research team belong to the Stanford Center for Research on Foundation Models (CRFM), the Stanford Natural Language Processing Group, and Google DeepMind. We thank the CRFM and the Stanford Institute for Human-Centered Artificial Intelligence (HAI) for supporting this work. Toyota Research Institute (TRI) and Schmidt Futures provided funds to support this work. The models released with this work were trained on Cloud TPU VMs, provided by Google’s TPU Research Cloud (TRC).
@article{thickstun2023anticipatory,
title={Anticipatory Music Transformer},
author={Thickstun, John and Hall, David and Donahue, Chris and Liang, Percy},
journal={arXiv preprint arXiv:2306.08620},
year={2023}
}
Uncurated Music Examples
Inputs for the following examples were randomly selected from the Lakh MIDI test set. Outputs of the Anticipatory Music Transformer were generated with nucleus sampling (p = 0.95). Outputs are not cherry-picked.
These examples were used for human evaluation of the Anticipatory Music Transformer. Model outputs were generated in two settings, controlled by two different types of input:
- Accompaniment: the model generates an infilling completion of music given a melody as input.
- Continuation: the model generates a temporal continuation of music given the beginning as input.
Accompaniment
For the accompaniment task, generation methods are given a prompt consisting of 5 seconds of a full ensemble and an additional 15 seconds of a single melodic instrument from that ensemble. Prompts are randomly sampled from the Lakh MIDI test set. The model is prompted to infill 15 seconds of musical content in a manner that is musically compatible with both the (past) ensemble and (contemperaneous) solo instrument prompt. We compare anticipation to two baseline infilling methods (Autoregressive and Retrieval). The generated completions are evaluated in Table 3 of the paper.
- Tonal controls
- Percussive controls
- Tonal completion
- Percussive completion
Continuation
For the continuation task, models are given a prompt consisting of 3 bars of a composition (4-6 seconds). Prompts are randomly sampled from the beginnings of compositions in the Lakh MIDI test set. The model is prompted to generate the remainder of a 20-second clip (approximately 15 seconds of musical content) in a manner that is musically compatible with the first 3 bars. We compare our best model (Medium - 360M parameters) to a smaller version of the same model (Small - 128M parameters) as well as the FIGARO Music Transformer and an autoregressive model trained without anticipation that uses a more standard (interarrival) tokenization of music. The generated completions are evaluated in Table 2 of the paper.
- Tonal controls
- Percussive controls
- Tonal completion
- Percussive completion