
DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining
Author: Sang Michael Xie
In this post, we introduce DoReMi, a novel algorithm that automatically weights how much of each data domain to use and results in 2.6x faster training on The Pile, along with an open-source PyTorch implementation.
TL;DR – Curating a good dataset is a crucial and underrated element of building large language models like PaLM. Typically, large-scale language modeling datasets combine data from a mixture of many domains. For example, The Pile, a large public text dataset, is composed of data from Wikipedia, books, and the web. One of the key decisions when training a large language model is how much of each domain to train on to produce a model that performs well for a wide variety of downstream tasks. As we’ll see later, training with optimized domain weights can make an 8B parameter model reach the baseline downstream accuracy 2.6x faster and eventually get 6.5% points better downstream performance! We’re also releasing an open-source PyTorch implementation of DoReMi as a tool to optimize data mixtures.
Large language models are expensive to train
Scaling up language models comes at a steep price. As an (outdated) example, Google’s PaLM, a 540B parameter model, trained on 780B tokens using over 6000 TPUs for 2 months, costing about 10 million dollars in opportunity cost for Google (those TPUs could have been making money for Google by renting them out on Google Cloud Platform). Generally, improving the training efficiency could save millions of dollars and weeks of monitoring for each training run.

In this post, we will focus on the input to the whole pipeline: the data. The large data scale is particularly important - even open-source models nowadays, like RedPajama, MPT, Falcon, and LLaMa, are trained on over 1T tokens. Because the datasets are so large and data-centric approaches are still mostly unexplored, improving the data could be especially impactful.
The data mixture problem
One of the key decisions when training a large language model is how much of each domain to train on to produce a model that performs well for a wide variety of downstream tasks. Previous approaches either determine the domain weights (the sampling probabilities for each domain) by intuition or by tuning against a set of downstream tasks. For example, The Pile heuristically chooses the domain weights, which would involve assumptions about the usefulness of each domain and how positive/negative transfer works between domains. Large language models like PaLM and GLaM tune the domain weights based on how a model trained on the domain weights does on a set of downstream tasks. This could require training many models to see the effect of changing the domain weights and risks overfitting the particular set of downstream tasks.
DoReMi automatically optimizes the data mixture
Enter DoReMi (Domain Reweighting with Minimax Optimization) — an algorithm for automatically optimizing the data mixture for language modeling datasets. Instead of optimizing domain weights based on a set of downstream tasks, DoReMi aims to find domain weights that produce models with good performance on all domains at the same time.
How does DoReMi accomplish this goal? Instead of optimizing the domain weights based on a set of downstream tasks, DoReMi minimizes the worst-case loss across the domains. However, naively optimizing for worst-case loss would just upweight the most noisy data. The main problem here is that every domain has a different optimal, irreducible loss (the entropy). To make the losses comparable across domains, DoReMi optimizes the worst-case excess loss (following DRO-LM and Prioritized training), which is the loss gap between the model being evaluated and a pretrained reference model.

The breakdown. DoReMi works in 3 steps. In Step 1, DoReMi trains a small reference model in a standard way using an initial set of reference domain weights. In Step 2, DoReMi uses the reference model to train a small proxy model, which optimizes for the worst-case excess loss via distributionally robust optimization (DRO). This step produces the optimized domain weights and a small proxy model as a side-product. Finally, in Step 3, DoReMi uses the optimized domain weights (which defines a reweighted dataset) to train a large language model more efficiently.
DoReMi: under the hood
Dynamic, learned data curation. Under the hood of Step 2, where most of the magic is happening, DoReMi uses an online learning-based DRO optimizer which dynamically updates the domain weights according to the excess loss on each domain. These domain weights will then rescale the loss on each domain. When the excess loss of a domain is high, the weight on that domain and consequently the loss on that domain will increase. The final domain weights are the averaged weights over training steps, which summarizes the importance of each domain over all of training. In this way, DoReMi curates the dataset in a dynamic way, taking into account how the model learns on each domain and how positive/negative transfer changes the losses across domains.
Excess loss. In the center of it all is the excess loss, which is the loss difference between the proxy model and the pretrained reference model. To get an intuition of how it works, when excess loss is…
- High: there is a lot of room to improve since the loss of the proxy model is high but the reference model was able to achieve low loss;
- Low: the data may be noisy / not learnable (high reference model loss) or the proxy model has already learned it (the proxy model loss is low).
DoReMi speeds up language model pretraining
We ran DoReMi on 280M parameter proxy and reference models to optimize domain weights on The Pile and the GLaM dataset, then used the domain weights to train 8B parameter models (over 30x larger). We also tested DoReMi across many other model sizes (280M, 510M, 760M, 1B), with similar gains.
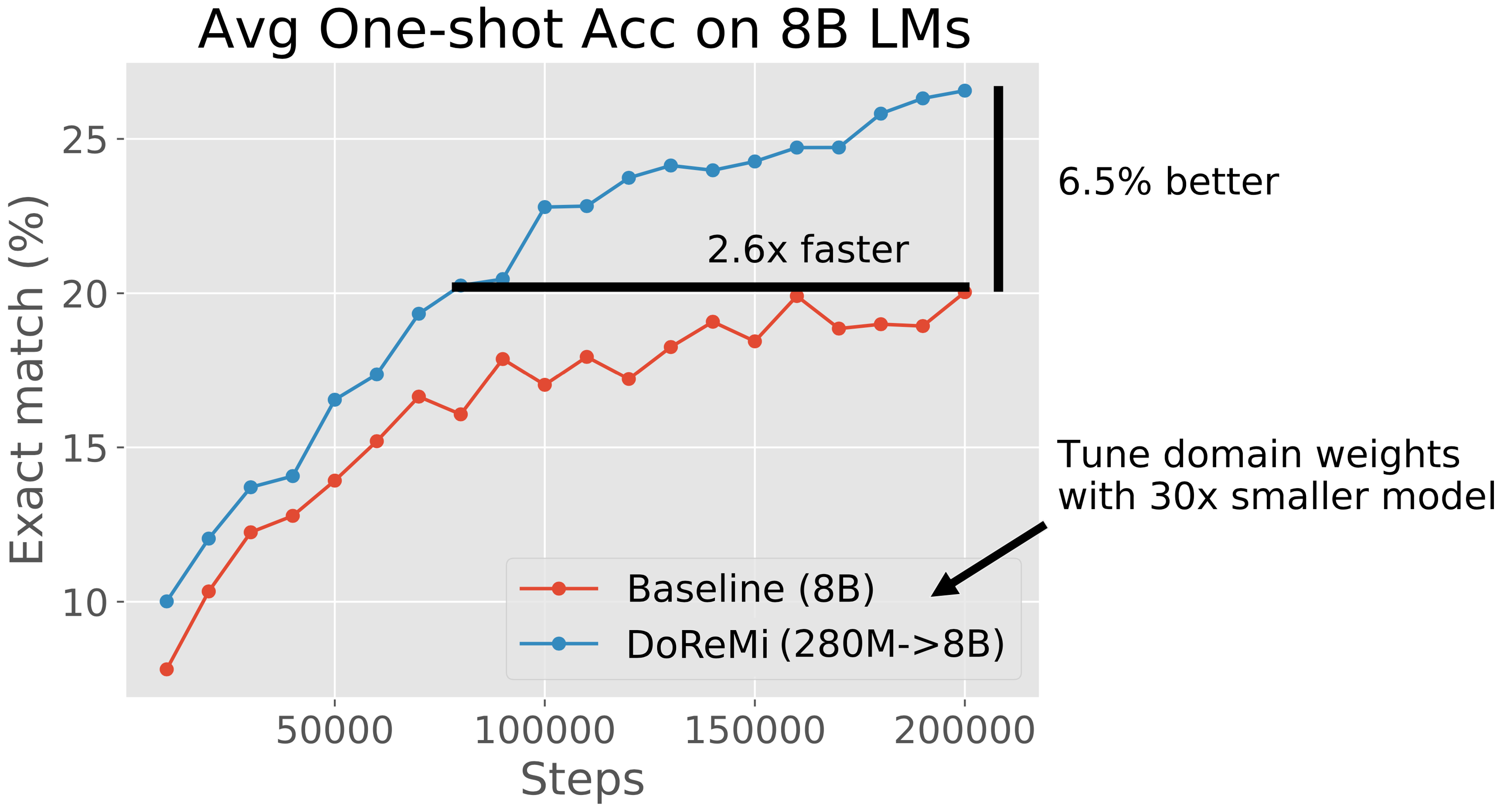
On downstream tasks, DoReMi improves the average one-shot accuracy over a baseline model trained on The Pile’s default domain weights by 6.5% points and achieves the baseline’s downstream accuracy 2.6x faster. For context, if the baseline costs $10M and 2 months to train, it would now cost $3.8M and about 3 weeks to train an equivalently performant model!
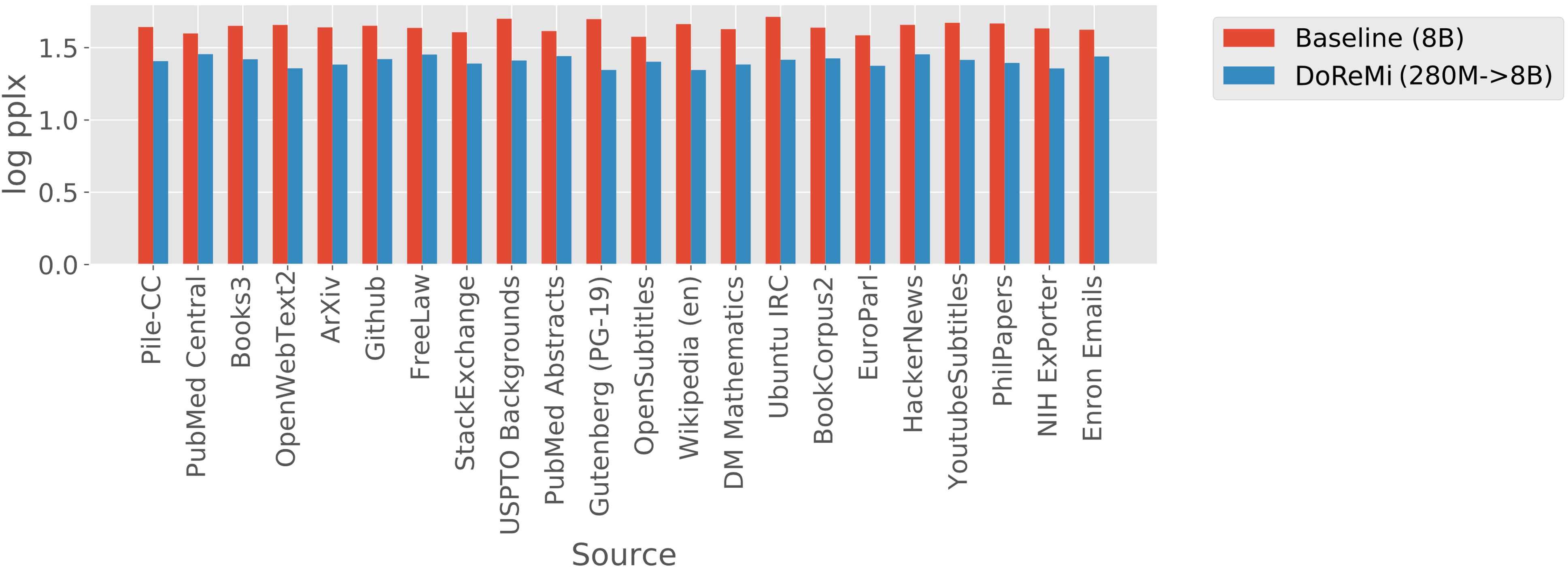
On The Pile, DoReMi reduces the perplexity on all domains over the baseline domain weights, even with it downweights a domain (so that domain gets less data).
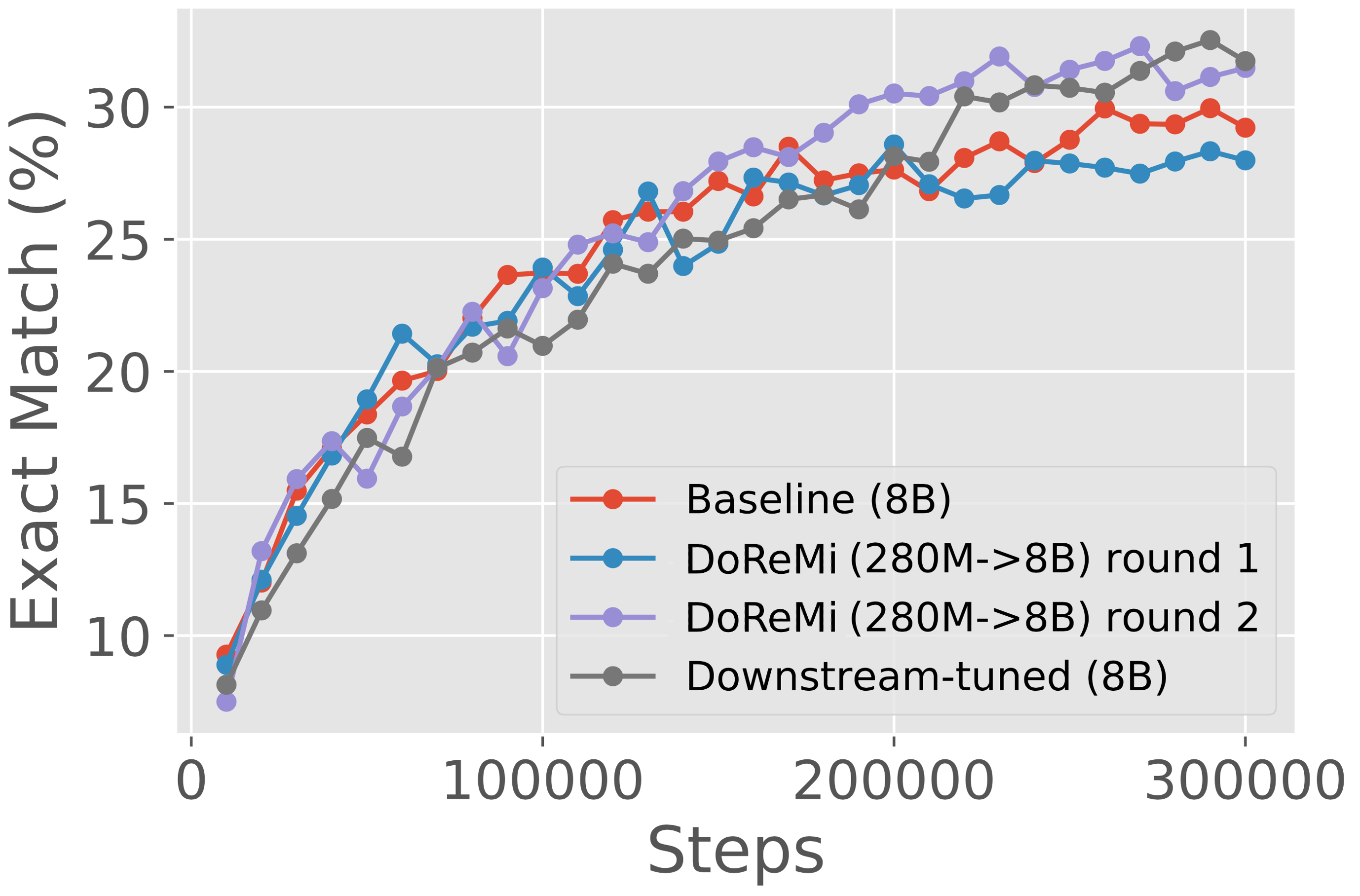
On the GLaM dataset, where domain weights tuned on downstream tasks are available, DoReMi even performs comparably to tuning domain weights on downstream tasks (the same ones that we evaluate on), but without using any downstream task information. However, this requires an extension to the DoReMi method which we call iterated DoReMi. In iterated DoReMi, we take the optimized domain weights from DoReMi and feed it back into Step 1 of the process, using it to train a new reference model. Starting from uniform reference domain weights, this process converges quickly (within 3 rounds), and we found that the second round of this process is able to match the performance of downstream-tuned domain weights.
Open-source codebase
We’re releasing an open-source codebase in PyTorch that implements the DoReMi algorithm, along with fast dataloaders for data mixtures and fast training using FlashAttention, all with the convenient Huggingface Trainer interface. This makes it easy to run DoReMi on their own dataset!
Wrapping up
The data mixture can have a large effect on the performance of the language model, and naïvely combining data domains together is suboptimal. To make it easy to improve language modeling datasets, we introduced DoReMi, an algorithm for optimizing the data mixture in language modeling datasets by just training two small models.
Acknowledgements
This research was a collaborative effort between Google and Stanford, conducted by Sang Michael Xie, Hieu Pham, Xuanyi Dong, Nan Du, Hanxiao Liu, Yifeng Lu, Percy Liang, Quoc Le, Tengyu Ma, and Adams Wei Yu. We thank Xiangning Chen, Andrew Dai, Zoubin Ghahramani, Balaji Lakshminarayanan, Paul Michel, Yonghui Wu, Steven Zheng, Chen Zhu and the broader Google Bard team members for insightful discussions and pointers. We also thank Ce Zhang, Heejin Jeong, and the Together team for providing compute resources to test the open-source codebase.