
HELM Lite: Lightweight and Broad Capabilities Evaluation
Authors: Percy Liang and Yifan Mai and Josselin Somerville and Farzaan Kaiyom and Tony Lee and Rishi Bommasani
Introducing HELM Lite v1.0.0, a lightweight benchmark for evaluating the general capabilities of language models.
It seems hard to believe that Holistic Evaluation of Language Models (HELM) was released only a year ago: November 2022 — ChatGPT had not even come out yet. The original goal of HELM was to holistically evaluate all the language models we had access to on a set of representative scenarios (capturing language abilities, reasoning abilities, knowledge, etc.) and multiple metrics (accuracy, calibration, robustness, fairness, bias, toxicity, efficiency). As a result, we ended up with something that was conceptually elegant, comprehensive…but quite heavyweight. We will refer to the benchmark introduced in the original paper as HELM Classic.
Fortunately, the HELM framework (on which HELM Classic was built), is highly modular and can support any choice of evaluations. Using the HELM framework, we have now created HELM Lite, a new benchmark that is lightweight yet broad. HELM Lite focuses only on capabilities. Safety will be covered by a new benchmark that we’re developing in partnership with MLCommons’s AI safety working group.
HELM Lite v1.0.0
HELM Lite simplifies HELM Classic in the following structural ways:
- HELM Classic performed 3 random seeds over different choices of in-context examples; HELM Lite uses only 1 random seed. While this does increase variance for individual results, the aggregate results over all scenarios will hopefully still be stable.
- HELM Classic perturbed evaluation instances multiple times to measure robustness and fairness; HELM Lite foregoes perturbations since robustness and fairness metrics (at least the simple ones we defined in HELM Classic) were well correlated with accuracy (Figure 24 of the HELM Classic paper).
- HELM Classic evaluated calibration; HELM Lite does not since many of the newer models do not expose probabilities via their APIs.
- HELM Classic evaluated perplexity on corpora; HELM Lite does not because newer models often do not expose probabilities. Moreover, computing perplexity for long documents requires painfully dealing with the many edge cases around tokenization and fixed context lengths.
- HELM Classic evaluated information retrieval (MS MARCO); HELM Lite does not because it was very expensive to run.
HELM Lite is not just a subset of HELM Classic. By simplifying, we now have room to expand to new domains. We have added medicine (MedQA), law (LegalBench), and machine translation (WMT14). Altogether, HELM Lite consists of the following scenarios:
- NarrativeQA: answer questions about stories from books and movie scripts, where the questions are human-written from the summaries (response: short answer).
- NaturalQuestions: answer questions from Google search queries on Wikipedia documents (response: short answer). We evaluate two versions, open book (where the relevant passage is given) and closed book (where only the question is given).
- OpenbookQA: answer questions on elementary science facts (response: multiple choice).
- MMLU: answer standardized exam questions from various technical topics (response: multiple choice). As with HELM Classic, we select 5 of the 57 subjects (abstract algebra, chemistry, computer security, econometrics, US foreign policy) for efficiency.
- MATH: solve competition math problems (response: short answer with chain of thought).
- GSM8K: solve grade school math problems (response: short answer with chain of thought).
- LegalBench: perform various tasks that require legal interpretation (response: multiple choice). We selected 5 of the 162 tasks for efficiency.
- MedQA: answer questions from the US medical licensing exams (response: multiple choice).
- WMT14: translate sentences from one language into English (response: sentence). We selected 5 source languages (Czech, German, French, Hindi, Russian) for efficiency.
We have evaluated the following language models, including both open and non-open ones:
- OpenAI: GPT-3.5 (text-davinci-002, text-davinci-003), ChatGPT (gpt-3.5-turbo-0613), GPT-4 (0613), GPT-4 Turbo (1106 preview)
- Anthropic: Claude Instant V1, Claude v1.3, Claude 2.0, Claude 2.1
- Google: PaLM 2 (bison, unicorn)
- Cohere: Command (default, light)
- Aleph Alpha: Luminous (base, extended, supreme)
- AI21: J2 (large, grande, jumbo)
- Writer: Palymra-X (v2, v3)
- Meta: LLaMA (65B), Llama 2 (7B, 13B, 70B)
- Mistral AI: Mistral (7B) Mixtral (8x7B)
- TII/UAE: Falcon (7B, 40B)
- 01.AI: Yi (6B, 34B)
HELM Lite is inspired by the simplicity of the Open LLM leaderboard (Hugging Face), though at least at this point, we include a broader set of scenarios and also include non-open models. The HELM framework is similar to BIG-bench, EleutherAI’s lm-evaluation-harness, and OpenAI evals, all of which also house a large number of scenarios, but HELM is more modular (e.g., scenarios and metrics are defined separately).
Each scenario (e.g., MedQA) in HELM Lite consists of a set of instances, where each instance consists of a textual input and a set of reference outputs. We take a maximum of 1000 instances. We evaluate an instance using in-context learning (as popularized by GPT-3). For each test instance, we select 5 in-context examples (or as many fit into the context window) and construct a prompt based on the adapter for multiple-choice and free-form generation. Scoring for multiple-choice is straightforward; scoring for generation is challenging in general, but since the responses are generally short and low entropy (question answering rather than story generation), we rely on metrics like F1, which are imperfect but we believe are still meaningful. One should always look at the full predictions (which are available on the website) to gain a deeper understanding.
Prompting assistant models
Evaluation based on in-context learning is suitable for base models such as Llama 2,
which behave like text-completion models.
We do not evaluate the assistant (instruct or chat) versions of these models.
But one problem is that recent APIs such as GPT-4 and Claude are assistant-like
and we do not have access to the underlying base model.
The responses of assistant models tend to be very verbose and not conform to the desired format (required for automatic evaluation), even when in-context examples are given and they are instructed to conform to the format. We have done some prompt engineering for these assistant models to coax them to generate outputs in the proper format. We made a decision to use generic prompts rather than customizing for each model and scenario. Specifically, for generation tasks, for GPT-4, Claude, and PaLM 2, we wrapped the prompt with the following to get it to perform in-context learning.
Here are some input-output examples. Read the examples carefully to figure out the mapping. The output of the last example is not given, and your job is to figure out what it is.
[prompt with in-context examples]
Please provide the output to this last example. It is critical to follow the format of the preceding outputs!
This improves the model’s outputs, but it is not perfect. Models sometimes still get penalized for outputting the correct answer in the wrong format (because they are too chatty). If the consumer of the output is a human, then the format is impertinent, but if the consumer is a program (in the case of building agents), then the format matters, so we find it justified to penalize a model for not conforming to the desired format (especially when explicitly instructed to follow the format). But when interpreting HELM Lite evaluation numbers, it’s important to remember that we are strict about format.
Results
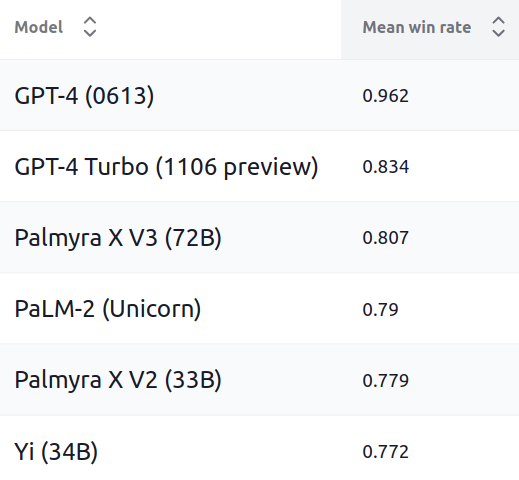
Finally, let us look at the results. For each scenario, we have a default accuracy metric (exact match, F1, etc.). For a fixed model, how do we combine these metrics into one number? One option would be to simply average the metrics, which is easy to understand and these averages are meaningful in isolation, but averaging different metrics is also dubious semantically. Instead, we decide to report the mean win rate, which is the fraction of times a model obtains a better score than another model, averaged across scenarios. Mean win rate is semantically meaningful even if different scenario metrics have different scales or units, but has the disadvantage that a mean win rate cannot be interpreted in isolation and depends on the full set of models in the comparison set.
Based on mean win rate, we see that GPT-4 tops the leaderboard. GPT-4 Turbo actually performs worse due the fact that it doesn’t follow instructions as well. PaLM 2 is also competitive as expected. Palmyra and Yi models are perhaps unexpectedly strong despite being much smaller models. This assessment is based on the current HELM Lite scenarios, which does not test for all capabilities (e.g., open-ended instruction following), so it’s important to not over interpret these rankings (or the rankings of any benchmark!). Your mileage might vary depending on your use case.
If we look across scenarios, the best model varies (it’s not always GPT-4). For example, Yi (34B) is the best model on NarrativeQA. PaLM 2 (bison, not unicorn) is the best model on NaturalQuestions (open book), but Llama 2 (70B) is the best model on NaturalQuestions (closed book). For the new scenarios: GPT-4 is best on LegalBench, GPT-4 Turbo is best on MedQA, and Palmyra X V3 (72B) is best on WMT14 (this is evaluated on BLEU-4, so take that result with a grain of salt).
Note that some of the numbers reported in HELM Lite are lower than the ones reported by the model developers. It’s hard to know why since the exact prompts for obtaining those results are often not made public (whereas all the HELM prompts and predictions are browsable on the website). Furthermore, not only do model developers use custom prompts, they sometimes perform more sophisticated methods like additional chain-of-thought and self-consistency ensembling to maximize the accuracy. We avoid such measures to keep things simple and consistent across both scenarios and models.
Looking forward, there are many aspects of evaluation not covered by HELM Lite.
- Safety. As mentioned earlier, we are building safety evaluations as part of the MLCommons AI safety working group.
- Instruction following. We would like to evaluate models’ instruction following and open-ended generation capabilities. A sister project, AlpacaEval, takes a first step in this direction, using model-graded evaluation for efficiency and reproducibility. The HELM framework supports model-graded evaluation, but we need to come up with more nuanced ways of measuring the effectiveness of instruction following.
- Dialogue. Instruction following can be seen as single-turn. We are also interested in evaluating multiturn dialogue. The LMSYS Chatbot Arena leaderboard is based on human pairwise comparisons, model-graded evaluations, and MMLU.
- Modalities beyond text. We have extended the HELM framework to evaluate text-to-image models (HEIM) and are working on evaluating general multimodal, vision-language models such as GPT-4V.
Each of these aspects (safety, instruction following, dialogue, and multimodality) will be a new benchmark built on the HELM framework. We are also porting DecodingTrust for evaluating trustworthiness and CLEVA for evaluating Chinese language models to the HELM framework. If you would like to port your benchmark to the HELM framework, please reach out!
Acknowledgements
We would like to thank OpenAI, Anthropic, Google, Cohere, Aleph Alpha, and AI21 for API credits to run their respective models and Together AI for credits to run all the open models. In addition, we would like to thank Thomas Liao and Zachary Witten on their prompting advice.