
The First Steps to Holistic Evaluation of Vision-Language Models
Authors: Tony Lee and Yifan Mai and Chi Heem Wong and Josselin Somerville Roberts and Michihiro Yasunaga and Farzaan Kaiyom and Rishi Bommasani and Percy Liang
Introduction
Vision-language models (VLMs), models that generate text given a hybrid text/visual prompt, have a wide range of use cases, including visual question-answering, text-driven image creation and alteration, image captioning, and robotics. However, our current understanding is limited by incomplete reporting — missing results for certain models on specific benchmarks and a notable absence of transparency regarding the prompting methodologies in the technical reports and blog posts released by the model developers.
To increase transparency and better understand VLMs, we introduce the first version of Holistic Evaluation of Vision-Language Models (VHELM) or VHELM v1.0 by extending the HELM framework to assess the performance of prominent VLMs.
We now have HELM Classic and Lite for language models, HEIM for text-to-image models, and VHELM to evaluate vision-language models. For this initial version of the VLM evaluation, we implemented three scenarios and supported 6 state-of-the-art VLMs to HELM.
Progress thus far
Vision-language models take text and visual input as a prompt to produce outputs, often in the form of text or visual content. In this initial effort, we focus on VLMs that can process interleaved text and images and generate text. VLMs can be applied to a diverse array of tasks, such as multimodal sentiment analysis, visual commonsense reasoning, and object detection given textual descriptions.

To evaluate VLMs, we start with the following scenarios (datasets):
- VQAv2: A dataset containing open-ended questions about real-world images.
- MMMU: A mix of multiple-choice and free-response questions across multiple academic disciplines that require college-level subject knowledge. We evaluate on all subjects and only have access to the answers on the validation set.
- VizWiz: A dataset of open-ended questions and images collected by visually impaired people.
In HELM, adaptation is the procedure that transforms a model, along with training instances, into a system that can make predictions on new instances. To evaluate VLMs, we initially support the same multiple-choice and generation adaptation methods with support for both zero-shot prompting and in-context learning as in HELM but with multimodal inputs.
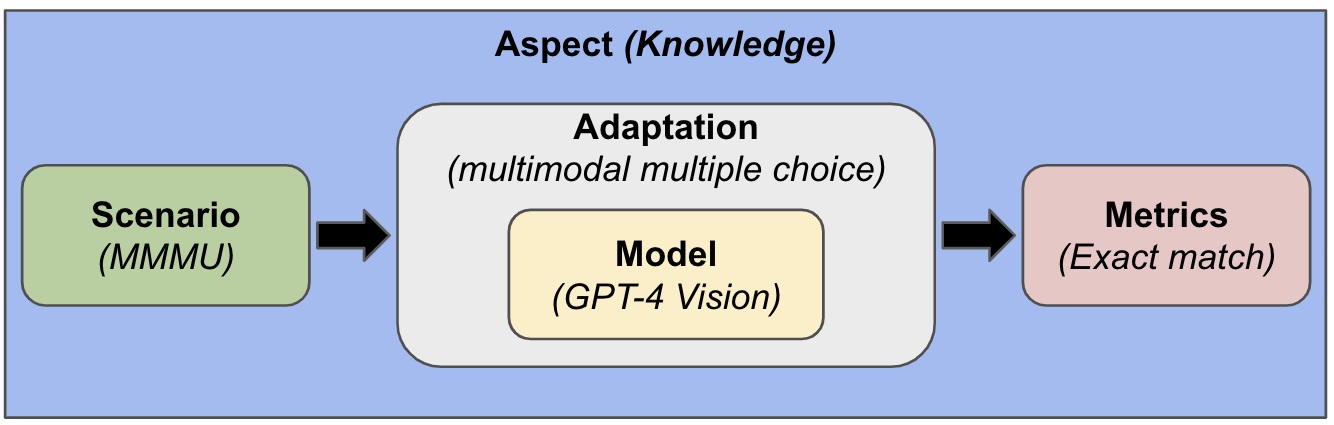
This expansion is feasible due to HELM’s modular design, which allows us to support new types of evaluation in the framework.
We evaluate the following 6 vision-language models varying in size and access from 4 different model developers with VHELM:
| Model | Developer | # of parameters | Access |
|---|---|---|---|
| GPT-4V | OpenAI | Unknown | Closed |
| Gemini 1.5 Pro | Unknown | Closed | |
| Gemini 1.0 Pro Vision | Unknown | Closed | |
| Claude 3 Sonnet | Anthropic | Unknown | Closed |
| Claude 3 Opus | Anthropic | Unknown | Closed |
| IDEFICS 2 | HuggingFace | 8B | Open |
In a zero-shot setting, we evaluate the models using up to 1000 examples from the three benchmarks. For MMMU, we evaluate on the multiple-choice questions only across all the subjects as they make up the vast majority of the examples. When computing the accuracy, we see if the model picks the letter corresponding to the correct answer. For VizWiz and VQAv2, we normalize (lowercase, remove punctuation, articles, and extra whitespace) the text from both the model’s output and the correct answers before checking if they are equal.
Results
All the inputs and outputs can be found here for full transparency. Through our initial analysis, we uncovered the following key empirical findings:
- According to the leaderboard, no single model uniformly outperforms the others across all scenarios. For example, Gemini 1.5 Pro achieves the best performance on two of the three scenarios, VizWiz and MMMU, but falls behind IDEFICS 2 on VQAv2.
- Gemini 1.5 Pro, followed by GPT-4V, exhibits the strongest world knowledge with the best performance on MMMU (59.8% accuracy).
- The open model, IDEFICS 2, is the best model on VQAv2 and the second-best model on VizWiz but performs the worst on the knowledge-intensive scenario, MMMU.
- There is a notable drop in exact match scores across all models on VizWiz compared to VQAv2, which could indicate that the VizWiz questions, created by visually impaired people, present unique challenges that are not as easily handled by the VLMs (Figure 1).
- Looking at the results of all the models for each of the benchmarks, it’s evident that there is room for improvement for vision-language models in general.

Limitations. Although it is a very popular benchmark for evaluating VLMs, open-ended QA benchmarks like VQAv2 have limitations on the expected answers when relying on purely automated metrics like exact match accuracy (Figure 2). A complete list of examples of these limitations can be found in GPT-4V’s raw predictions to VQAv2 prompts.
VHELM v1.0 is by no means holistic, as we are only testing a few capabilities of these models with the three benchmarks. These findings are preliminary as we plan to continuously update and expand VHELM with more scenarios and models, filling in the gaps of missing results for specific scenario/model pairs as this project progresses.

Summary
We have presented VHELM v1.0, which extends HELM to evaluate vision-language models. We started with 3 scenarios (VQAv2, MMMU, and VizWiz), which were used to evaluate 6 vision-language models. For complete transparency, we release all the raw prompts and predictions in addition to the numbers.
Supporting the evaluation of VLMs in HELM was just the first step. We plan to add more scenarios, models, and metrics to measure the different capabilities and risks of vision-language models. We also encourage the community to contribute new models, scenarios, and metrics to improve the evaluation of vision-language models.
Acknowledgments
We would like to thank OpenAI, Anthropic, and Google for API credits to evaluate their models and Google for funding.
Citation
If our work resonates with you, we kindly ask you to reference this blog post:
@misc{vhelm_initial,
author = {Tony Lee and Yifan Mai and Chi Heem Wong and Josselin Somerville Roberts and Michihiro Yasunaga and Faarzan Kaiyom and Rishi Bommasani and Percy Liang},
title = {The First Steps to Holistic Evaluation of Vision-Language Models},
month = {May},
year = {2024},
url = {https://crfm.stanford.edu/2024/05/08/vhelm-initial.html},
}