This is an old version of the Foundation Model Transparency Index, released in October 2023. For the latest version, click here.
Context. Foundation models like GPT-4 and Llama 2 are used by millions of people. While
the societal impact of these models is rising, transparency is on the decline.
If this trend continues, foundation models could become just as opaque as social media platforms
and other previous technologies, replicating their failure modes.
Design. We introduce the Foundation Model Transparency Index to assess the transparency
of foundation model developers. We design the Index around 100 transparency indicators, which
codify transparency for foundation models, the resources required to build them, and their use
in the AI supply chain.
Execution. For the 2023 Index, we score 10 leading developers against our 100 indicators.
This provides a snapshot of transparency across the AI ecosystem. All developers have
significant room
for improvement that we will aim to track in the future versions of the Index.
Key Findings
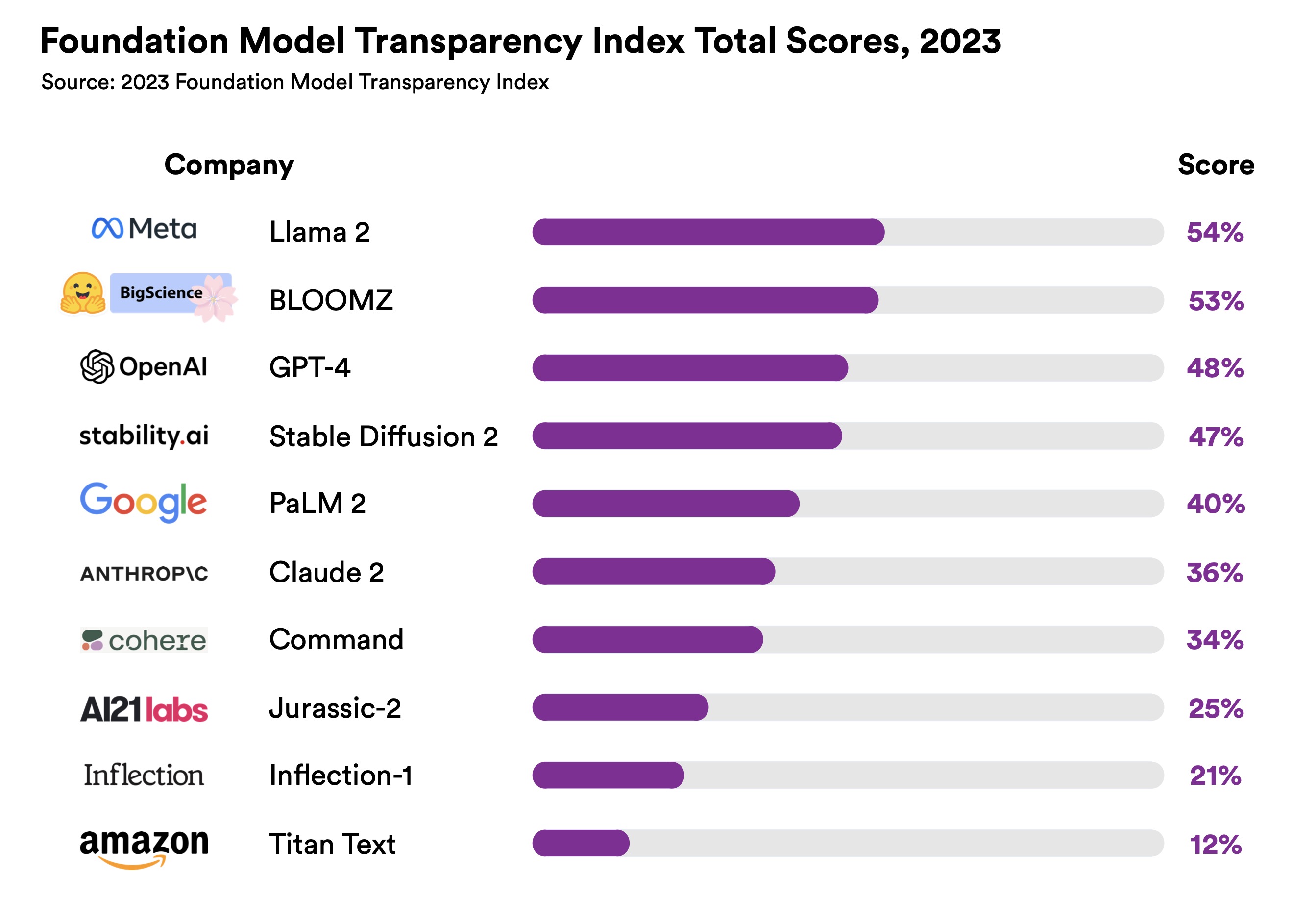
The top-scoring model scores only 54 out of 100. No major foundation model developer
is close to providing adequate transparency, revealing a fundamental lack of transparency in
the AI industry.
The mean score is a just 37%. Yet, 82 of the indicators are satisfied by at least
one developer, meaning that developers can significantly improve transparency by adopting
best practices from their competitors.
Open foundation model developers lead the way. Two of the three open foundation model
developers get the two highest scores. Both
allow
their model weights to be downloaded. Stability AI, the third open foundation model developer,
is a close fourth, behind OpenAI.
Indicators
We define 100 indicators that comprehensively characterize
transparency for foundation model developers.
We divide our indicators into three broad domains:
Upstream. The upstream indicators specify the ingredients and processes involved in building a
foundation model, such as the computational resources, data, and labor used to build foundation models.
Full list of upstream indicators.
Model. The model indicators specify the properties and function of the foundation model, such as
the model's architecture, capabilities, and risks
Full list of model indicators.
Downstream. The downstream indicators specify how the foundation model is distributed and used,
such as the the model's impact on users, any updates to the model, and the policies that govern its use.
Full list of downstream indicators.
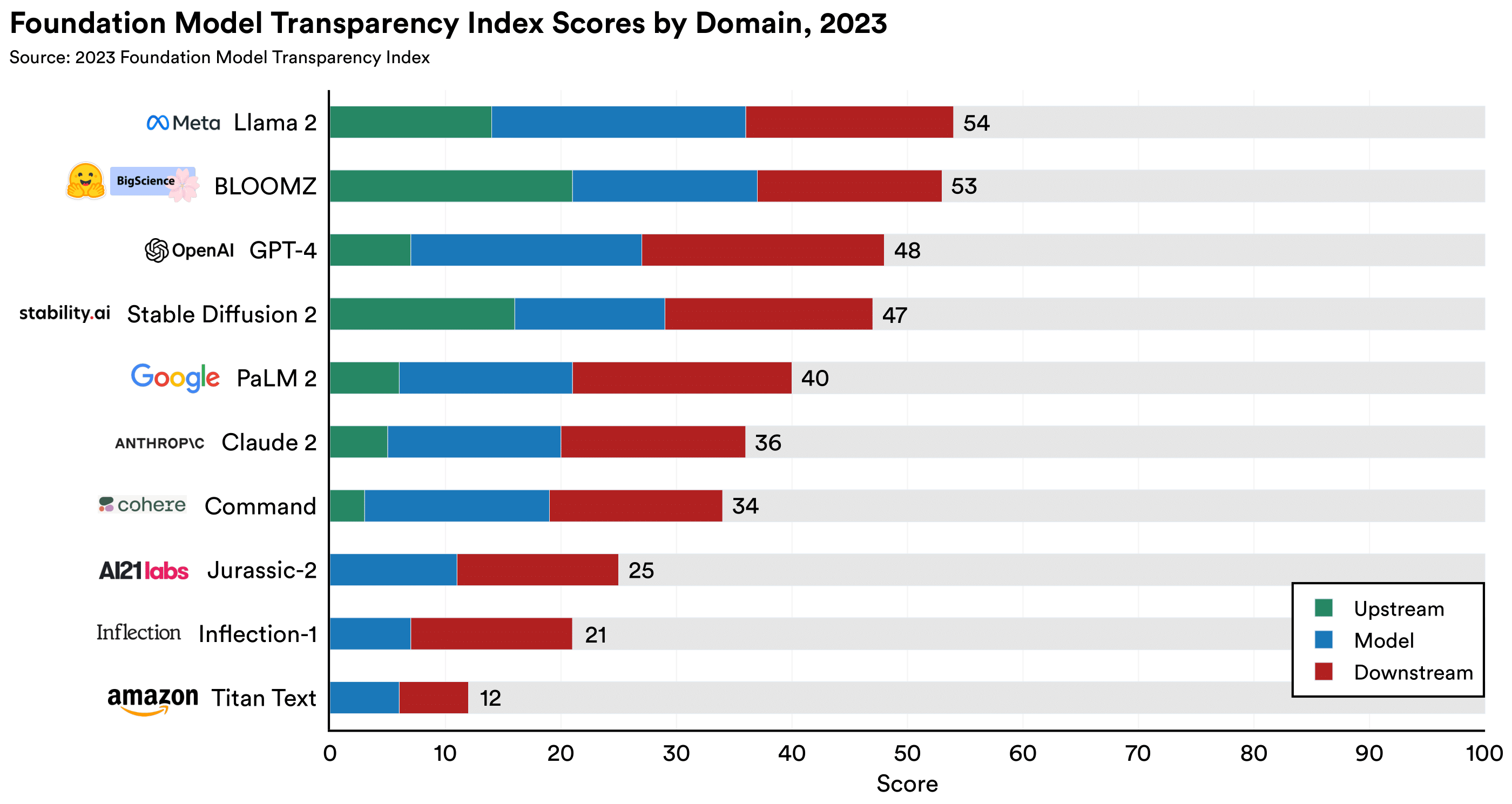
Scores for the 10 foundation model providers, broken down by domain.
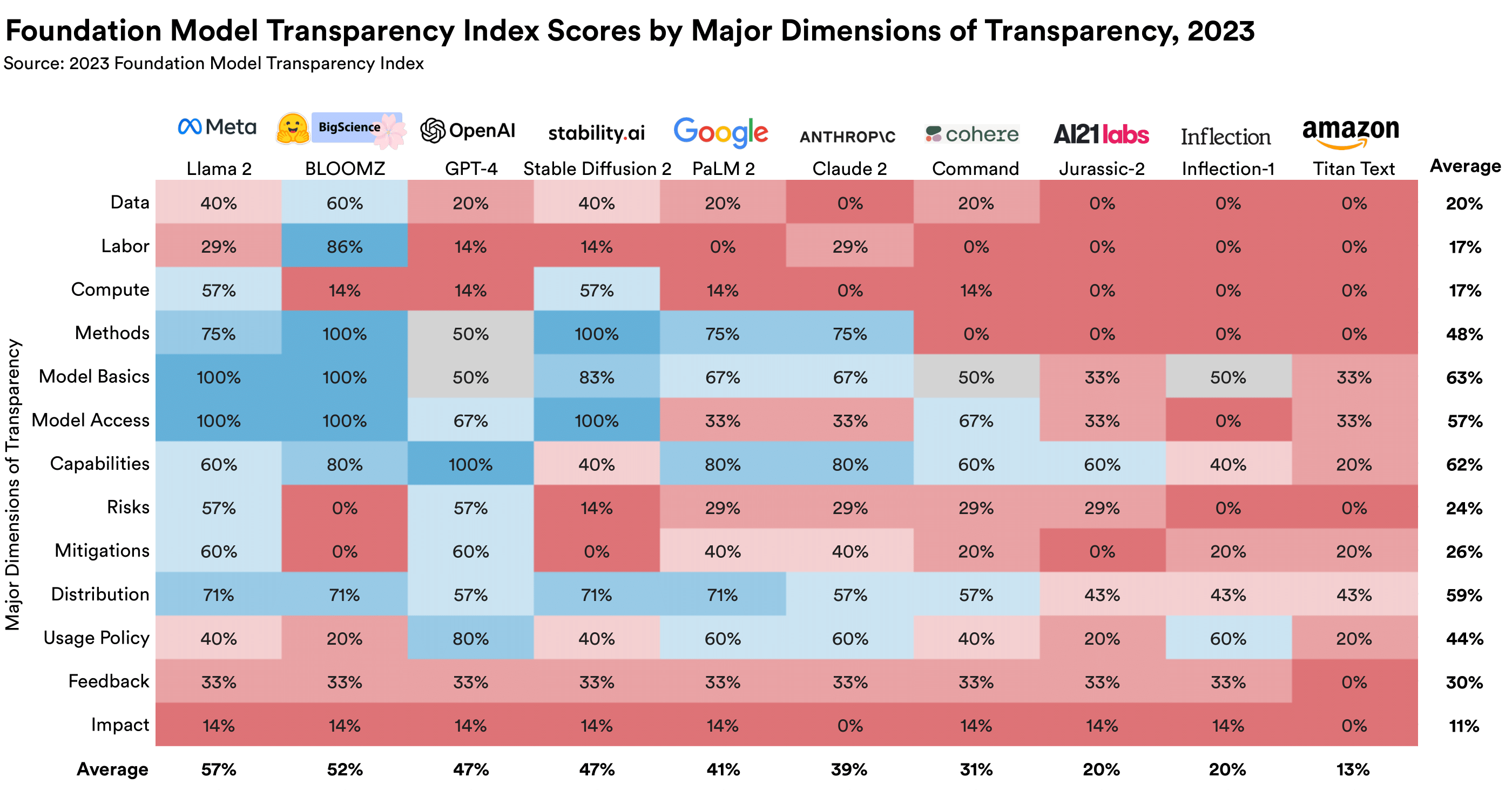
Scores by subdomain
In addition to the top-level domains (upstream, model, and downstream), we also group indicators together
into subdomains. Subdomains provide a more granular and incisive analysis, as shown in the figure below.
Each of the subdomains in the figure includes three or more indicators.
Data, labor, and compute are blind spots across developers.
Developers are least transparent with respect to the resources required to build foundation models.
This stems from low performance on the data, labor, and compute subdomains.
All developers' scores sum to just 20%, 17%, and 17% of the total available points
for data, labor, and compute.
Developers are more transparent about user data protection and the basic functionality of their
model.
Developers score well on indicators related to user data protection (67%),
basic details about how their foundation models are developed (63%),
the capabilities of their models (62%), and their limitations (60%).
This reflects some baseline level of transparency across developers regarding how they process user data
and the basic functionality of their products.
There is room for improvement even in subdomains where developers are most transparent.
No developer provides information about the process by which it provides access to usage data.
Only a handful of developers are transparent in demonstrating the limitations of their models
or having third parties evaluate models' capabilities.
While every developer describes the input and output modality of its model, only three disclose the
model components and only two disclose the model size.
Scores for the 10 foundation model providers broken down by 13 subdomains,
each of which have three or more indicators.
Analysis at the level of major subdomains reveals actionable insight into what types of
transparency or
opacity lead to the above findings.
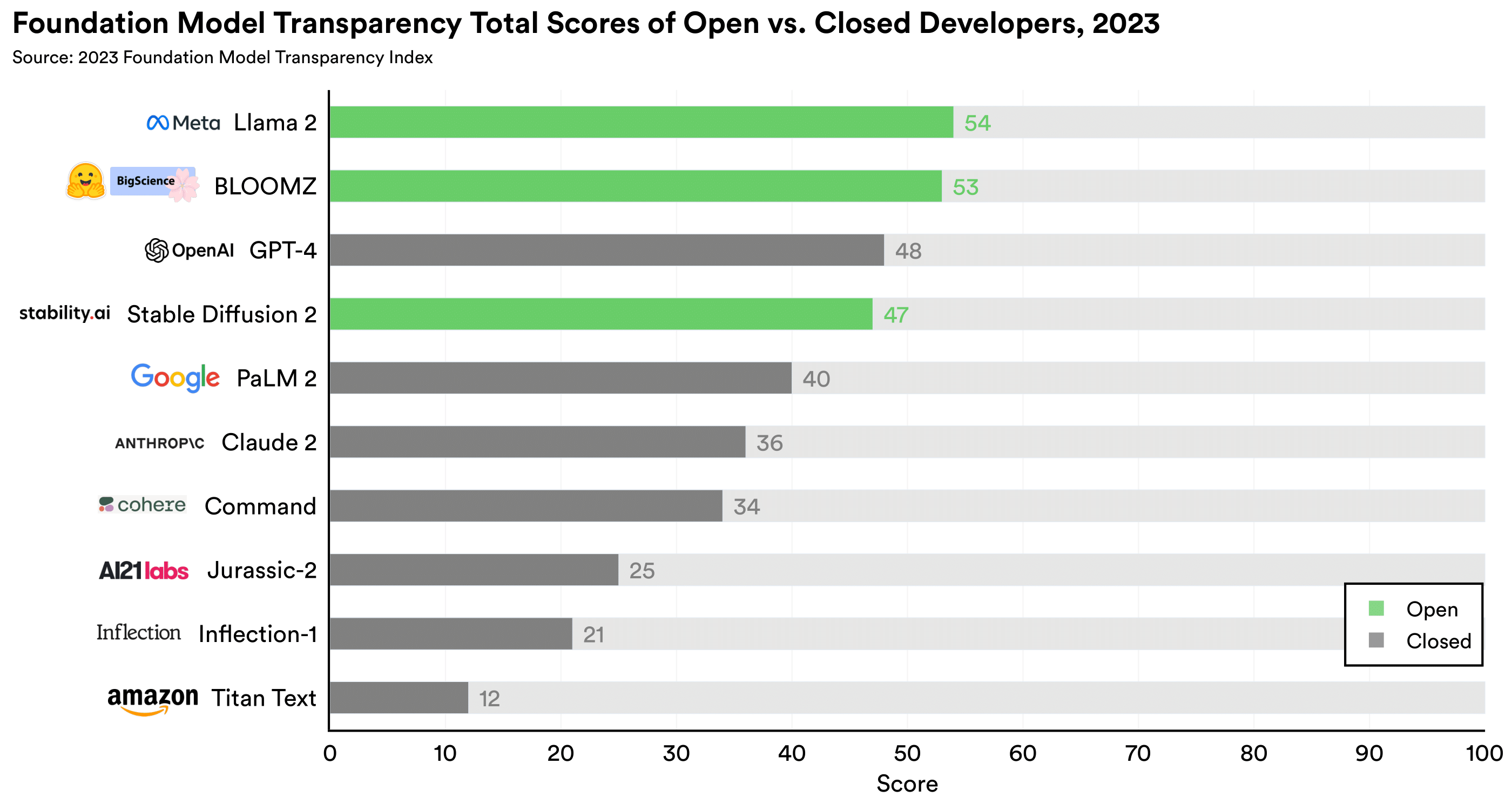
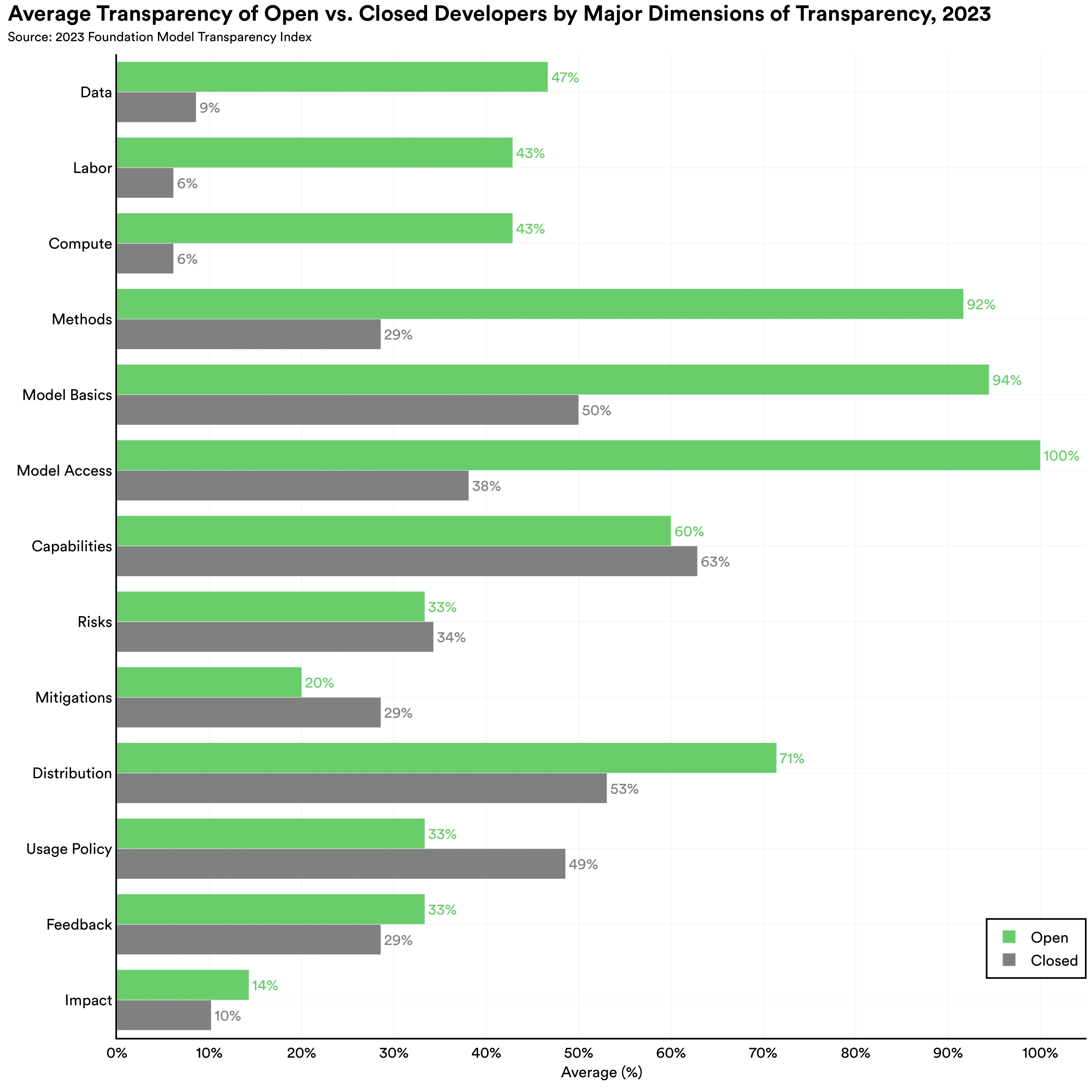
Open vs. Closed models
One of the most contentious policy debates in AI today is whether AI models should be open or closed.
While the release strategies of AI are not
binary, for the analysis below, we label models whose weights are
broadly downloadable as open. Open models lead the way: We find that two of the three open models (Meta's
Llama 2 and Hugging Face's
BLOOMZ) score greater than or equal to the best closed model (as shown in the
figure on the left), with Stability AI's Stable Diffusion 2 right behind OpenAI's GPT-4. Much of this
disparity is driven the lack of transparency of closed developers on
upstream
issues such as the data, labor, and compute used to build the model (as shown in the figure on the right).
Open models (Meta's Llama-2, Hugging Face's BLOOMZ, and
Stability AI's Stable Diffusion 2) lead the way.
The disparity between open and closed models is driven by upstream indicators, such
as
details about the data, labor, and compute used to develop
the model
Methodology
Targets. We selected 10 major foundation model developers based on their influence,
heterogeneity,
and status as established companies. We assessed these companies on the basis of their most salient
and capable foundation model.
Information gathering. We systematically gathered information made publicly available by the
developer as of September 15, 2023.
Initial scoring. For each developer, two researchers scored the 100 indicators, assessing
whether the developer satisfied the indicator on the basis of public information. We compared scores and
resolved disagreements through discussion.
Company response. We shared the initial scores with leaders at each company, encouraging them to
contest scores they disagreed with. We addressed their reviews, finalizing scores along with
justifications and sources.
Board
The FMTI advisory board will work directly with the Index team, advising the design, execution, and
presentation
of subsequent iterations of the Index. Concretely, the Index team will meet regularly with the board to
discuss key decision points: How is transparency best measured, how should companies disclose the relevant
information publicly, how should scores be computed/presented, and how should findings be communicated to
companies, policymakers, and the public? The Index aims to measure transparency to bring about greater
transparency in the foundation model ecosystem: the board’s collective wisdom will guide the Index team in
achieving these goals. (Home)
Board members
Arvind Narayanan is a professor of computer science at Princeton University and the director of
the Center
for Information Technology Policy. He co-authored a textbook on fairness and machine learning and is
currently co-authoring a book on AI snake oil. He led the Princeton Web Transparency and Accountability
Project to uncover how companies collect and use our personal information. His work was among the first
to
show how machine learning reflects cultural stereotypes, and his doctoral research showed the
fundamental
limits of de-identification. Narayanan is a recipient of the Presidential Early Career Award for
Scientists
and Engineers (PECASE).
Daniel E. Ho is the William Benjamin Scott and Luna M. Scott Professor of Law, professor of
political science, professor of computer science (by courtesy), senior fellow at the Stanford Institute
for
Human-Centered Artificial Intelligence (HAI), senior fellow at the Stanford Institute for Economic
Policy
Research, and director of the Regulation, Evaluation, and Governance Lab (RegLab). Ho serves on the
National
Artificial Intelligence Advisory Committee (NAIAC), advising the White House on AI policy, as senior
advisor
on Responsible AI at the U.S. Department of Labor and as special advisor to the ABA Task Force on Law
and
Artificial Intelligence. His scholarship focuses on administrative law, regulatory policy, and
antidiscrimination law. With the RegLab, his work has developed high-impact demonstration projects of
data
science and machine learning in public policy.
Danielle Allen is James Bryant Conant University Professor at Harvard University. She is a
professor of political philosophy, ethics, and public policy and director of the Democratic Knowledge
Project and of the Allen Lab for Democracy Renovation. She is also a seasoned nonprofit leader,
democracy
advocate, national voice on AI and tech ethics, distinguished author, and mom. A past chair of the
Mellon
Foundation and Pulitzer Prize Board, and former Dean of Humanities at the University of Chicago, she is
a
member of the American Academy of Arts and Sciences and American Philosophical Society. Her many books
include the widely acclaimed Talking to Strangers: Anxieties of Citizenship Since Brown v Board of
Education; Our Declaration: A Reading of the Declaration of Independence in Defense of Equality; Cuz:
The
Life and Times of Michael A.; Democracy in the Time of Coronavirus; and Justice by Means of Democracy.
She
writes a column on constitutional democracy for the Washington Post. She is also a co-chair for the Our
Common Purpose Commission and founder and president for Partners In Democracy, where she advocates for
democracy reform to create greater voice and access in our democracy, and to drive progress toward a new
social contract that serves and includes us all.
Daron Acemoglu is an Institute Professor of Economics in the Department of Economics at the
Massachusetts Institute of Technology and also affiliated with the National Bureau of Economic Research,
and
the Center for Economic Policy Research. His research covers a wide range of areas within economics,
including political economy, economic development and growth, human capital theory, growth theory,
innovation, search theory, network economics and learning. He is an elected fellow of the National
Academy
of Sciences, the British Academy, the American Philosophical Society, the Turkish Academy of Sciences,
the
American Academy of Arts and Sciences, the Econometric Society, the European Economic Association, and
the
Society of Labor Economists.
Rumman Chowdhury is the CEO and co-founder of Humane Intelligence, a tech nonprofit that
creates methods of public evaluations of AI models, as well as a Responsible AI affiliate at Harvard’s
Berkman Klein Center for Internet and Society. She is also a research affiliate at the Minderoo Center
for
Democracy and Technology at Cambridge University and a visiting researcher at the NYU Tandon School of
Engineering. Previously, Dr. Chowdhury was the director of the META (ML Ethics, Transparency, and
Accountability) team at Twitter, leading a team of applied researchers and engineers to identify and
mitigate algorithmic harms on the platform. She was named one of BBC’s 100 Women, recognized as one of
the
Bay Area’s top 40 under 40, and a member of the British Royal Society of the Arts (RSA). She has also
been
named by Forbes as one of Five Who are Shaping AI.